
Latest Blog Posts





You can access my five most recent posts using the links above.
Looking for a different post?
From March 2010 through February 2018 I blogged at https://edtechfrontier.com.
Starting February 2022 I’ve been blogging here on this site.
For earlier posts dating back to February 2022 scroll down or use Search:
The Tragedy of AI (and what to do about it)
Image adapted from Tragedy and Comedy by Tim Green CC BY
A tragedy is characterized by four things:
A heroic noble protagonist
Fatal flaw(s)
An inevitable downfall
Catharsis

Heroic Noble AI image adapated fom Super Heros by 5chw4r7z CC BY
Fatal Flaws image adapted from They Always Focus On Our Flaws by Theilr CC BY-SA
Inevitable Downfall image adapted from The Downfall Of Machismo by Tman CC BY-NC-SA
Catharsis image adapted from Catharsis by Jason Jacobs CC BY
I’m doing a presentation titled “The Tragedy of AI (and what to do about it)” Monday June 23, 2025 at the Association of Learning Technology (ALT) Open Education Conference (OER25) in London England. The theme of this event is “Speaking Truth to Power: Open Education and AI in the Age of Populism”.
To complement and accompany my presentation I’ve written this essay blog post in two parts.
Part one, “The Tragedy of AI” establishes why AI is a tragedy. It reveals fatal flaws of AI. It shows how these fatal flaws risk leading to tragic inevitable downfall. This Tragedy of AI essay specifically focuses on the negative impact AI is having on the social agreements and fundamental principles that underlie open education, open science, and other open knowledge practices.
Part two, “Catharsis” explores the “(and what to do about it)” part of the Tragedy of AI. It puts forward options for taking action to address or prevent the tragedy of AI. It defines actions in ways that fit with open and deal with the fatal flaws of AI in ways that mitigate downfall.
PART ONE - The Tragedy of AI
AI as Heroic Noble Protagonist

Much has been written about the exceptional capabilities of AI. The OER25 conference program is chock a block full of such sessions. This post doesn’t delve into that, enough is being said.
The focus of this post is instead on the other three characteristics of a tragedy - fatal flaws, inevitable downfall, and catharsis.
The Fatal Flaws of AI

There are five fatal flaws of AI:
Tragedy of the Capitalism over the Commons
Taking without consent
Demotivating sharing
Breaking reciprocity, and
Bleeding open dry
Lets dig in to each of them.
AI Fatal Flaw #1 - Tragedy of the Capitalism over the Commons
Everyone knows, as Darcy Norman puts it,
“GenAI tools, based on Large Language Models (LLMs), are built by extracting content from across the internet—often without clear consent or compensation. This extraction-based origin demands caution.”
I put it a bit more forcefully. AI as a robbing, a plunder, a pillaging of a public commons - all of the Internet. In creating their Large Language Models developers of AI have helped themselves to all the content you and I have on the Internet. AI as an appropriation of a commons with little to no regard for the commons itself or the social norms associated with it.
Robin Sloan in his essay “Is it okay?” says:
“How do you make a language model? Goes like this: erect a trellis of code, then allow the real program to grow, its development guided by a grueling training process, fueled by reams of text, mostly scraped from the internet. Now. I want to take a moment to think together about a question with no remaining practical importance, but persistent moral urgency:
Is that okay?
The question doesn’t have any practical importance because the AI companies — and not only the companies, but the enthusiasts, all over the world — are going to keep doing what they’re doing, no matter what.
The question does still have moral urgency because, at its heart, it’s a question about the things people all share together: the hows and the whys of humanity’s common inheritance. There’s hardly anything bigger.”
In 1968 Joseph Hardin wrote the “Tragedy of the Commons”. In it he asks us to:
“Picture a pasture open to all. It is to be expected that each herdsman will try to keep as many cattle as possible on the commons. Such an arrangement may work reasonably satisfactorily for centuries because tribal wars, poaching, and disease keep the numbers of both man and beast well below the carrying capacity of the land.”
But what happens when the capacity of the land is met? Hardin says;
“The rational herdsman concludes that the only sensible course for him to pursue is to add another animal to his herd. And another; and another.... But this is the conclusion reached by each and every rational herdsman sharing a commons. Therein is the tragedy. Each man is locked into a system that compels him to increase his herd without limit-in a world that is limited.”
The effects of this self-interest over group interest Hardin suggests are overgrazing and a destruction of the commons to the detriment of all.
Louis Villa in his "My commons roller coaster" says:
"Whether or not the web was a “commons” is complicated, so I don’t want to push that label too hard. (As just one example, there was not much boundary setting—one of Ostrom’s signals of a traditional common pool resource.) But whether or not it was, strictly speaking, a “commons”, it was inarguably the greatest repository of knowledge the world had ever seen. Among other reasons, this was in large part because the combination of fair use and technical accessibility had rendered it searchable. That accessibility enabled a lot of good things too—everything from language frequency analysis to the Wayback Machine, one of the great archives of human history.
But in any case it’s clear that those labels, if they ever applied, very much merit the past tense. Search is broken; paywalls are rising; and our collective ability to learn from this is declining. It’s a little much to say that this paper is like satellite photos of the Amazon burning... but it really does feel like a norm, and a resource, are being destroyed very quickly, and right before our eyes."

Image adapted from of Global Carbon Monoxide by NASA CC BY
AI is a tragedy based on AI developers assuming everything on the web is there for the taking, acting autonomously, out of pure self-interest without interaction or consideration of the commons or the people that make that commons. In doing so AI negatively impacts practices of sharing and openness risking the destruction of the very commons on which it relies.
Anna Tumadóttir in her article “Reciprocity in the Age of AI” says:
“What we ultimately want, and what we believe we need, is a commons that is strong, resilient, growing, useful (to machines and to humans)—all the good things, frankly. But as our open infrastructures mature they become increasingly taken for granted, and the feeling that “this is for all of us” is replaced with “everyone is entitled to this”. While this sounds the same, it really isn’t. Because with entitlement comes misuse, the social contract breaks, reciprocation evaporates, and ultimately the magic weakens.
Hardin’s Tragedy of the Commons intuitively resonates with us. Air pollution, over grazing, deforestation, climate change and other global challenges align with his notion that people always act out of selfish self interest. But the tragedy of the commons is a concept, a theory, and as Elinor Ostrom’s Nobel prize winning work showed, it is not how a commons works in practice.
The reality is that AI is not a Tragedy of the Commons. It is a Tragedy of Capitalism. It is a tragedy of self-interest and the belief in competition over cooperation. It is a tragedy of the relentless pursuit of growth and profit no matter what the cost.
In part two “Catharsis” I’ll describe some of the ways Ostrom discovered people mitigate the potential for a tragedy of the commons and explore how we can apply these ideas to AI and our open work.
For those of you interested in exploring more about the differences between how a commons works and how capitalism works I highly recommend these resources:
The Serviceberry - Abundance and Reciprocity in the Natural World by Robin Wall Kimmerer. This beautiful book published in 2024 is an eloquent exploration of the issue based on lessons from the natural world.
The Gift - How the Creative Spirit Transforms the World by Lewis Hyde. This book explores old gift-giving cultures and their relation to commodity societies.
Doughnut Economics - Seven Ways to Think Like a 21st Century Economist by Kate Raworth. Doughnut economics, is a visual framework for sustainable development. The framework is shaped like a doughnut, hence its name. It explores the creation of an alternate economy that meets the needs of people without overshooting Earth's ecological ceiling re-framing economic problems in the process.
Made With Creative Commons by Paul Stacey and Sarah Hinchliff Pearson. While working at Creative Commons I co-wrote this book with Sarah. It is guide to sharing your knowledge and creativity with the world, and sustaining your operation while you do.
AI Fatal Flaw #2 - Taking Without Consent
As Daniel Campos notes,
AI is constructed non-consensually on the back of copyrighted material
This is one of the greatest stains on this technology, period.
People’s work was taken, without consent, and it is now being used to generate profit for parties visible and not.
Thing is, this is unsustainable for all parties. The technology requires ongoing training to remain relevant. Everyone who is part of its value chain, in the long term, must be represented in both its profits and the general framework for participation.
AI developers did not seek permission. They mined any works they wanted. No care was taken as to whether the works are under copyright or have an open license. Everything on the Internet, content of all kinds, posts, books, journal articles, music, … it didn’t matter, AI developers view all such resources as legitimate sources of data for its models. The more data mined the better the AI model.
As Johana Bhuiyan notes in “Companies building AI-powered tech are using your posts” reports:
“"Even if you haven’t opted in to letting them use your data to train their AI, some companies have opted you in by default. Figuring out how to stop them from hoovering up your data to train their AI isn’t exactly intuitive. Left to their own devices, more than 300,000 Instagram users have posted a message on their stories in recent days stating they do not give Meta permission to use any of their personal information to inform their AI. To be clear, just like the Facebook statuses of yore, a simple Instagram post will not do anything to stop Meta from using your data in this way.
This is not a new practice as Bhuiyan notes:
“Default opt-ins are an industry-wide issue. A recent report by the Federal Trade Commission (FTC) on the data practices of nine social media and streaming platforms including WhatsApp, Facebook, YouTube and Amazon found that nearly all of them fed people’s personal information into automated systems with no comprehensive or transparent way for users to opt out.
Overall, there was a lack of access, choice, control, transparency, explainability and interpretability relating to the companies’ use of automated systems,” the FTC report reads.”
AI developers are facing lawsuits over their use of content without consent. Creators are advocating for consent, credit and compensation. AI developers seem to be speaking out of two sides of their mouths on this issue. On the one side they are claiming their use of content is allowed under copyright fair use (in the US) or text and data mining rules. On the other they are simultaneously pursuing licensing deals with major media rights holders.
Consent to use is not just about data scraped from the web. It’s also about the data associated with your use of the AI itself. Sadly the business models of AI are further entrenching have’s vs have nots. If you are using a free version of an AI application your prompts and outputs are, by default, being used to train the AI. If you are using paid versions of an AI application your prompts and outputs are not being used to train the AI. For example Google’s Gemini AI terms of use says this:
“When you use Paid Services, including, for example, the paid quota of the Gemini API, Google doesn't use your prompts (including associated system instructions, cached content, and files such as images, videos, or documents) or responses to improve our products.”
“When you use Unpaid Services, including, for example, Google AI Studio and the unpaid quota on Gemini API, Google uses the content you submit to the Services and any generated responses to provide, improve, and develop Google products and services and machine learning technologies, including Google's enterprise features, products, and services.”
So if you can afford to pay to use AI your prompts and outputs aren’t used to train the AI. If you are less well off and can’t afford to pay then you pay by agreeing to have your data used.
AI Fatal Flaw #3 - Demotivating Sharing
Sharing is central to open practices whether that be open education, open science, open data, open culture or any of the many other forms of open. Creative Commons licenses have been a key means by which sharing of content has been enabled.
However, as Anna Tumadóttir, CEO of Creative Commons, says in her article "Reciprocity in the Age of AI":
“Since the inception of CC (Creative Commons), there have been two sides to the licenses. There’s the legal side, which describes in explicit and legally sound terms, what rights are granted for a particular item. But, equally there’s the social side, which is communicated when someone applies the CC icons. The icon acts as identification, a badge, a symbol that we are in this together, and that’s why we are sharing. Whether it’s scientific research, educational materials, or poetry, when it’s marked with a CC license it’s also accompanied by a social agreement which is anchored in reciprocity. This is for all of us.
But, with the mainstream emergence of generative AI, that social agreement has come into question and come under threat, with knock-on consequences for the greater commons. Current approaches to building commercial foundation models lack reciprocity. No one shares photos of ptarmigans to get rich, no one contributes to articles about Huldufólk seeking fame. It is about sharing knowledge. But when that shared knowledge is opaquely ingested, credit is not given, and the crawlers ramp up server activity (and fees) to the degree where the human experience is degraded, folks are demotivated to continue contributing.”
Sadly AI demotivates sharing.

Image adapted from Sharing With Others by Frank Homp CC BY
AI Fatal Flaw #4 - Breaking Reciprocity
At this point AI is a permissionless, acquisition and assertion of the right to use the works of others. It is a utilization of others works for profit without reciprocity. By breaking with the reciprocal social exchange principle that involves the giving and receiving of benefits or actions between individuals AI engages in negative reciprocity gaining more out of the exchange than the public and naturally people feel wronged.

Image adapted from Reciprocity by Keith Solomon CC BY-NC-SA
AI developers do not seek permission. They mine any works they want. They don’t care whether the works used are under copyright or have an open license. Everything on the Internet, books, journal articles, music, … it doesn’t matter, all such resources are considered legitimate sources of data for its models.
As Frank Pasquale and Haochen Sun note,
“Most AI firms are not compensating creative workers for composing the songs, drawing the images, and writing both the fiction and nonfiction books that their models need in order to function. AI thus threatens not only to undermine the livelihoods of authors, artists, and other creatives, but also to destabilize the very knowledge ecosystem it relies on.”
They go on to note that legislators agree,
“The situation strikes many policymakers as deeply unfair and undesirable. As the Communications and Digital Committee of the United Kingdom’s House of Lords has concluded, “[w]e do not believe it is fair for tech firms to use rightsholder data for commercial purposes without permission or compensation, and to gain vast financial rewards in the process.”
And this is not just an issue for proprietary works. Openly licensed and peer reviewed sources of data are considered high quality and AI prizes such data sources. But AI violates and degrades the integrity of open sharing by taking without giving. As Stephanie Decker notes in The Open Access – AI Conundrum: Does Free to Read Mean Free to Train?,
"The central issue remains that commercial AI companies extract significant economic value from OA content without necessarily returning value to the academic ecosystem that produced it, while at the same time disrupting academic incentive structures and attribution mechanisms."
Creative Commons CEO Anna Tumadóttir says,
“Reciprocity in the age of AI means fostering a mutually beneficial relationship between creators/data stewards and AI model builders. For AI model builders who disproportionately benefit from the commons, reciprocity is a way of giving back to the commons that is community and context specific.
(And in case it wasn’t already clear, this piece isn’t about policy or laws, but about centering people).
This is where our values need to enter the equation: we cannot sit neutrally by and allow “this is for everyone” to mean that grossly disproportionate benefits of the commons accrue to the few. That our shared knowledge pools get siphoned off and kept from us.
We believe reciprocity must be embedded in the AI ecosystem in order to uphold the social contract behind sharing. If you benefit from the commons, and (critically) if you are in a position to give back to the commons, you should. Because the commons are for everyone, which means we all need to uphold the value of the commons by contributing in whatever way is appropriate.
There never has been, nor should there be, a mandatory 1:1 exchange between each individual and the commons. What’s appropriate then, as a way to give back?”
We’ll explore answers to this question in the second part of this essay “Catharsis”.
AI Fatal Flaw #5 - Bleeding Open Dry
Molly White in her post “Wait, not like that”: Free and open access in the age of generative AI” says,
“The real threat isn’t AI using open knowledge — it’s AI companies killing the projects that make knowledge free. The true threat from AI is that they will stifle open knowledge repositories benefiting from the labor, money, and care that goes into supporting them while also bleeding them dry. It’s that trillion dollar companies become the sole arbiters of access to knowledge after subsuming the painstaking work of those who made knowledge free to all, killing those projects in the process.”
AI does not acknowledge, care for, or contribute to the stewardship of the commons on which it relies.

Bleeding Open Dry image adapted from Pavement Drain With Patched Cracks photo by Paul Stacey CC BY-SA
Molly goes on to say:
“Anyone at an AI company who stops to think for half a second should be able to recognize they have a vampiric relationship with the commons. While they rely on these repositories for their sustenance, their adversarial and disrespectful relationships with creators reduce the incentives for anyone to make their work publicly available going forward (freely licensed or otherwise). They drain resources from maintainers of those common repositories often without any compensation. They reduce the visibility of the original sources, leaving people unaware that they can or should contribute towards maintaining such valuable projects. AI companies should want a thriving open access ecosystem, ensuring that the models they trained on Wikipedia in 2020 can be continually expanded and updated. Even if AI companies don’t care about the benefit to the common good, it shouldn’t be hard for them to understand that by bleeding these projects dry, they are destroying their own food supply.
And yet many AI companies seem to give very little thought to this, seemingly looking only at the months in front of them rather than operating on years-long timescales.”

Vampire by Alvaro Tapia licensed CC BY-NC-ND
AI is vampiric sucking the lifeblood out of the corpus of all human knowledge and selling it back to us as a monthly subscription.

Image adapted from Hacker Memes based on original Twonks comic by Steve Nelson
The Inevitable Downfall

The fatal flaws of AI lead to an inevitable downfall. The very things AI relies on:
The Commons
Consent and willing participation
Sharing of high quality, thriving, evolving data
Reciprocity
Openness
are its fatal flaws.
Tragedy of Capitalism over the Commons
Taking without consent
Demotivating sharing
Breaking reciprocity, and
Bleeding open dry
The fatal flaws not only have the potential for an inevitable downfall of AI but the downfall of open education, open science and other open practices too.
Every time I use AI I feel like I am aiding and abetting this tragedy and downfall. In my use I condone its taking.
The current issues around ChatGPT and Studio Ghibli describe it well. Shanti Escalante-De Mattei says in her article “The ChatGPT Studio Ghibli Trend Weaponizes “Harmlessness” to Manufacture Consent”:
“Every time a user transforms a selfie, family photo or cat pic into a Ghibli-esque image, they normalize the ability of AI to steal aesthetics, associations, and affinities that artists spend a lifetime building. Participatory propaganda doesn’t require users to understand the philosophical debates about artists’ rights, or legal ones around copyright and consent. Simply by participating they help Altman and his competitors win the battle of public opinion. For many, the Ghibli images will be their first contact with generative AI. For more informed users, the flood of images reinforces the inevitability that AI will re-shape our world. It’s particularly cruel that Miyazaki’s style has become the AI vanguard, given that he famously stuck to laborious hand-drawn animation even as the industry shifted to computer-generated animation.”
She concludes:
"It is laborious, loving, useful work that imparts self-knowledge and the understanding of shared struggle and humanity. You cannot skip to the end. You cannot just generate the artwork or the essay and get the learning and the satisfaction that the work imparts. When you forgo that labor, you let fascists, corporations, and all manner of elite actors make the act of expressing yourself so easy that you feel free, even agentive, as they take your rights from you."
I have used AI. But this is not the kind of relationship I want. I’m not a fan of the enshitification of the Internet and much of AI is following the enshitification model flooding us with slop (deepfakes, misinformation, personality appropriation, bias, … - need I go on?) and exploitive business models.
Oh sure there have been publications about the ethics of AI and attempts to regulate (at least in the EU) but to date there has been no effective repercussion to the tragedy of AI. There is no change in behaviour no adjustment of course. If anything, there is a race to commercialization, economic growth, and global dominance - regulations, guardrails, social agreements be damned.
AI’s trampling of the commons puts it at odds with open.
Should our response simply be one of acceptance?
Everybody Knows but nobody does anything?
Is there no course of action to address or prevent the tragedy of AI?
I think there are lots of emerging options.
I have hope.
So lets move on to “Catharsis”.
PART Two - Catharsis

In this Catharsis section we shift from the Tragedy of AI to the “(and what to do about it)” part. What are options for taking action to address or prevent the tragedy of AI? What actions can the open community take to deal with the fatal flaws of AI in ways that mitigate downfall?
Anna Tumadóttir, CEO of Creative Commons says:
“There never has been, nor should there be, a mandatory 1:1 exchange between each individual and the commons. What’s appropriate then, as a way to give back? So many possibilities come to mind, including:
Increasing agency as a means to achieve reciprocity by allowing data holders to signal their preferences for AI training
Credit, in the form of attribution, when possible
Open infrastructure support
Cooperative dataset development
Putting model weights or other components into the commons
Catharsis can take many forms.
Building on Anna’s list here are five catharsis actions I think the open community can pursue to resolve the fatal flaws of AI and avoid the tragedy:
Social Agreements & Regulations
Preference Signals
Reciprocity
Public AI
Collaborative open data set creation
Lets explore each of these.
AI Catharsis #1 - Social Agreements & Regulations
Samuel Moore in "Governing the Scholarly Commons" says:
"The question, then, is not whether AI is inherently good or bad but more concerning who controls it and with what motivation. If it is answerable to affected communities, ethicists and technological experts, AI may develop in a more productive way than if it is governed by the needs of shareholders and profit-seeking companies. The problem of AI governance – in the context of academic knowledge production – is the focus of this report."
He goes on to suggest:
"The governance of knowledge production is currently weighted heavily in favour of the market, which is to say that decisions to implement a technology or business model are determined by how profitable they are, how much labour they save, or how financially efficient they are. I am therefore interested in ways to keep the power of the market in check in the service of more responsible AI development."

Social Agreements and Regulations image adapted from Agreement by Takashi Toyooka CC BY-NC
Moore's report looks at a range of different strategies for governing the implementation of AI as a scholarly commons. Options for good governance of AI in academic knowledge production include:
Commons-based approaches
Academic governance
Academic "citizen" assemblies
These all have merit.
Commons-based approaches have a high fit with open education and open science.
Nobel prize winning Elinor Ostrom studied many different commons. She found that the tragedy of the commons is not inevitable, as Hardin thought. Instead, if commons participants decide to cooperate with one another, communicate, monitor each other’s use, and enforce rules for managing it, they can avoid the tragedy.
Open education and open science have been functioning in just such a cooperative manner but AI disrupts that practice.
It is in the interest of AI developers and the open community to work together in resolving the fatal flaws and avoid a shared tragedy.
What we need is dialogue, communication and relationship building between the open community and AI developers. There are lots of AI applications targeting education. Their development efforts are proceeding with little to no engagement with the open education community. Open education could step up and take an active leading role in seeking to communicate and influence how AI development for education takes place. But we can’t do that in isolation from the AI developers themselves.
We could for example, seek to work with efforts like Current AI who have a focus area specifically relating to Open supporting open standards and tools that make AI accessible and adaptable for everyone.
Alek Tarkowski in his article "Data Commons Can Save Open AI" says:
"We must do everything in our power to ensure that future datasets are built upon a data commons with stewardship and control."
His recently released report, “Data Governance in Open Source AI- Enabling Responsible and Systemic Access” argues that collective action is needed to release more data and improve data governance to balance open sharing with responsible release.
Consortia of open organizations could collaborate and propose solutions to the fatal flaws. Everyone acknowledges the need for AI guardrails. Clearly rules and agreements are needed. But these can come in many forms ranging from social norms, to policy, and regulations. How would the open community define these?
Over one hundred countries signed on to the "Statement on Inclusive and Sustainable Artificial Intelligence for People and the Planet" committing to:
"Initiate a Global Dialogue on AI governance and the Independent International Scientific Panel on AI and to align on-going governance efforts, ensuring complementarity and avoiding duplication."
How might the open community participate and provide input into such efforts?
Governments are responsible for regulations with the EU AI regulation being the prime example to date. Perhaps AI, developed with public funds, ought to be open to the public that paid for it in a similar manner as with open science and open education?
Over time the legality related to copyright lawsuits AI faces will emerge. But it will take a long time and it is highly politicized as highlighted in Copyright Office head fired after reporting AI training isn’t always fair use. Nevertheless it seems likely there will be new rules that seek to strike some kind of effective balance between the public interests, maintaining a thriving creative community and allowing technological innovation to flourish. It seems prudent that we make an effort to define what that looks like for open education and open science.
One option is for us to define norms and social agreements. We've seen some related action around efforts to define what "open source" means in the context of AI models. But to date there is no similar effort around defining what open means in the context of AI in open education and open science. There are lots of efforts around ethics in relation to AI but not so much around open.
In Governing the Commons, Elinor Ostrom summarized eight design principles associated with creating a sustainable commons:
1. Clearly defined boundaries
2. Congruence between appropriation and provision rules and local conditions
3. Collective-choice arrangements
4. Monitoring
5. Graduated sanctions
6. Conflict-resolution mechanisms
7. Minimal recognition of rights to organize
8. Nested enterprises
These design principles are worth considering as a framework for devising open norms and agreements related commons based approaches to AI.
But there are many more options.
Molly White in her article “Wait, not like that”: Free and open access in the age of generative AI, says,
“It would be very wise for these [AI] companies to immediately begin prioritizing the ongoing health of the commons, so that they do not wind up strangling their golden goose. It would also be very wise for the rest of us to not rely on AI companies to suddenly, miraculously come to their senses or develop a conscience en masse.
Instead, we must ensure that mechanisms are in place to force AI companies to engage with these repositories on their creators' terms.
There are ways to do it: models like Wikimedia Enterprise, which welcomes AI companies to use Wikimedia-hosted data, but requires them to do so using paid, high-volume pipes to ensure that they do not clog up the system for everyone else and to make them financially support the extra load they’re placing on the project’s infrastructure. Creative Commons is experimenting with the idea of “preference signals” — a non-copyright-based model by which to communicate to AI companies and other entities the terms on which they may or may not reuse CC licensed work. Everyday people need to be given the tools — both legal and technical — to enforce their own preferences around how their works are used.
Some might argue that if AI companies are already ignoring copyright and training on all-rights-reserved works, they'll simply ignore these mechanisms too. But there's a crucial difference: rather than relying on murky copyright claims or threatening to expand copyright in ways that would ultimately harm creators, we can establish clear legal frameworks around consent and compensation that build on existing labor and contract law. Just as unions have successfully negotiated terms of use, ethical engagement, and fair compensation in the past, collective bargaining can help establish enforceable agreements between AI companies, those freely licensing their works, and communities maintaining open knowledge repositories. These agreements would cover not just financial compensation for infrastructure costs, but also requirements around attribution, ethical use, and reinvestment in the commons.
The future of free and open access isn't about saying “wait, not like that” — it’s about saying "yes, like that, but under fair terms”. With fair compensation for infrastructure costs. With attribution and avenues by which new people can discover and give back to the underlying commons. With deep respect for the communities that make the commons — and the tools that build off them — possible. Only then can we truly build that world where every single human being can freely share in the sum of all knowledge.”
I think this entire list of suggestions is a good harbinger of what is to come. Of particular note is the shift from using copyright as the primary legal framework for open to one that uses labor and contract law to enact AI social agreements and regulations.
AI Catharsis #2 - Signal Preferences
I think signal preferences have a lot of potential.

Signal Preferences image adapted from Smoke Signals by Ashok Boghani CC BY-NC
As Molly noted, Creative Commons (CC) is experimenting with the idea of preference signals. In 2024 a Creative Commons Position Paper on Preference Signals was released that gives a good overview of what is being considered. This paper notes:
“What is new with generative AI is that the unanticipated uses are happening at scale. With concentrated power there is a risk of concentrated benefits and creators are questioning anew whether the bargain is worth it. The creative works are being used outside of their original context in a way that does not distribute any of the usual rewards back to the creator, either financial or reputational.”
One signal preferencing approach focuses on making it possible to signal opt-out vs opt-in. By default AI developers automatically opted us all in to their use of our data. This could be changed by regulation. But in the interim there is interest in a technical opt-out signalling preference that allows creators to prevent their content from being used for AI training.
The most promising solution seems to be Robots.txt. Audrey Hingle and Mallory Knodel note in their article "Robots.txt Is Having a Moment: Here's Why We Should Care" note:
“Robots.txt remains important as a foundational tool due to its widespread adoption and familiarity among website owners and developers. It provides a straightforward mechanism for declaring basic crawling permissions, offering a common starting point from which more advanced and specific solutions can evolve.”
However, they go on to note challenges:
“Robots.txt is primarily useful for website owners and publishers who control their own domains and can easily specify crawling rules. It doesn't effectively address content shared across multiple platforms or websites, nor does it give individual content creators, such as artists, musicians, writers, and other creative professionals, a way to easily communicate their consent preferences when they publish their work on third party sites, or when their work is used by others.”
Opt-in vs opt-out has largely focused on providing a way for websites and end users to opt out of having AI use their data for training. I’d love to see opt-in options that give users options for opting in to having their data used for AI that serves the public interest rather than for big tech for-profit shareholders.
Creative Commons is taking a different approach from opt-in vs opt-out. In their Position Paper on Preference Signals they say:
“CC’s approach is to reject the all-or-nothing framework and create options for sharing that reflect a more generous and collaborative spirit than default copyright. The CC licenses exist on a spectrum of permissiveness, all underpinned by the goal of enabling access to and sharing of knowledge and creativity as part of a global commons, built on mutual cooperation and shared values.”
They go on to note:
“We have uncovered many of the limitations of using instruments such as robots.txt as an indicator of opt-in or opt-out for generative AI training. In many cases, robots.txt and a website’s terms of service are inconsistent, and robots.txt is a limiting protocol when it comes to creator content in the commons as a public good (including, but not limited to art, culture, science, journalism, scientific data). Further, approaches that propagate the limiting binary of blunt instruments of opt-out do not take into consideration the values and social norms embedded in sharing content on the web. CC’s approach is to develop and advocate for tools that empower creators and contribute to a healthy and ethical commons for the public good.”
Creative Commons has made a lot of progress on this and on June 25, 2025 they are hosting a CC Signals Kickoff event. There invitation to this event says:
“We are building a standardized, global mechanism called CC signals that aims to increase the agency of those creating and stewarding the content that is relied upon for AI training. We invite you to join us as we officially kick off the CC signals project. During this kickoff event, you’ll hear from members of the CC team and community who will share an outline of the first public proposal of the CC signals framework. We will also provide resources that give background information and explore early thinking on legal and technical implementation of CC signals. Our goal is to set up members of the CC global community to engage with this proposal so that you can provide input and recommendations that will strengthen the initiative as we build toward pilot implementation later this year. This is a shared challenge, and a shared opportunity. Whether you're a funder, developer, policymaker, educator, platform operator, or creator, your participation matters. Join us.”
Anna CEO of Creative Commons says:
“Part of CC being louder about our values is also taking action in the form of a social protocol that is built on preference signals, a simple pact between those stewarding data and those reusing it for generative AI. Like CC licenses, they are aimed at well-meaning actors and designed to establish new social norms around sharing and access based on reciprocity. We’re actively working alongside values-aligned partners to pilot a framework that makes reciprocity actionable when shared knowledge is used to train generative AI.”
A key emphasis is that these preference signals are focused on reciprocity. I think we’ll see preferences address reciprocity in ways that involve direct or indirect financial subsidization, mutual exchange non-monetary contribution, and credit/attribution recognition.
One of the best things about existing CC licenses is their use of icons and human readable deeds. I expect these signal preferences to follow that successful format with icons that symbolize preferences and easy to read deeds that clearly specify the terms of the social agreement.
AI Catharsis #3 - Reciprocity
This is, perhaps, the single biggest fatal flaw of AI. I applaud CC’s efforts to address it.
Given the volume of data used to train AI models the value of any one creators data is likely very small. One precedent for thinking about this is music streaming where creators get a small fraction of a cent per stream. However, as seen by AI licensing deals, AI developers want to work more with large collection holders rather than individual creators. Reciprocity at the aggregate level rather than at the individual level.
Paul Keller in "AI, the Commons, and the limits of copyright" has a novel suggestion:
“We should look for a new social contract, such as the United Nations Global Digital Compact, to determine how to spend the surplus generated from the digital commons. A social contract would require any commercial deployment of generative AI systems trained on large amounts of publicly available content to pay a levy. The proceeds of such a levy system should then support the digital commons or contribute to other efforts that benefit humanity, for example, by paying into a global climate adaptation fund. Such a system would ensure that commercial actors who benefit disproportionately from access to the “sum of human knowledge in digital, scrapable form” can only do so under the condition that they also contribute back to the commons.”

Image adapted from Reciprocity by Keith Solomon CC BY-NC-SA
If AI is going to take and benefit from the commons it surely ought to contribute back to it? Do we, the open community, have ideas for how AI can contribute back to the commons?
The open community tends to openly license and share resources not with the expectation of personal financial gain but with the aim of enabling a commons that benefits all. What can AI developers contribute to a commons benefitting us all?
One consideration is credit and attribution. Creators of all types value reputation gain through acknowledgement and recognition. This is especially so in open where open science and open education communities use Creative Commons licenses that all mandate attribution. More broadly, citations and references are a core and essential practice in education and research.
By not providing credit and attribution AI breaks the reciprocal social norms of academia. This is one area where academia is well positioned to push back and advocate for fully referenced AI outputs. Credit, in the form of attribution, should be the default. At the very least the datasets on which the model is trained should be fully disclosed.
AI Catharsis #4 - Public AI
Another form reciprocity could take is support for open infrastructure that supports the commons more broadly. Open infrastructures are technologies, services, and resources provided and managed by non-commercial organizations. A big issue with AI is the complexity of the technology stack involved with developing and using AI applications. Reciprocity could entail creation of alternatives to for-profit AI in the form of open infrastructure for Public AI.
Open infrastructures are technologies, services, and resources provided and managed by non-commercial organisations. A big issue with AI is the complexity of the technology stack involved with developing and using AI applications. Open infrastructure can establish an alternative to For-profit AI in the form of Public AI.
In a recently published "Public AI - A Public Alternative to Private AI Dominance" blog post and paper Alek Tarkowski, Felix Sieker, Lea Gimpel, and Cailean Osborne write:
"Today’s most advanced AI systems and foundation models are largely proprietary and controlled by a small number of companies. There is a striking lack of viable public or open alternatives. This gap means that cutting-edge AI remains in the hands of a select few, with limited orientation toward the public interest, accountability or oversight.
Public AI is a vision of AI systems that are meaningful alternatives to the status quo. In order to serve the public interest, they are developed under transparent governance, with public accountability, equitable access to core components (such as data and models), and a clear focus on public-purpose functions."
Public AI serves the public interest. This seems common ground with open education and open science.

Public AI image adapted from What Is For the Public Good? photo by Paul Stacey CC BY-SA
The report goes on to say:
“A vision for public AI needs to take into account today’s constraints at the compute, data and model layers of the AI stack, and offer actionable steps to overcome these limitations. This white paper offers a clear overview of AI systems and infrastructures conceptualized as a stack of interdependent elements, with compute, data and models as its core layers.
It also identifies critical bottlenecks and dependencies in today’s AI ecosystem, where dependency on dominant or even monopolistic commercial solutions constrains development of public alternatives. It highlights the need for policy approaches that can orchestrate resources and various actors across layers, rather than attempting complete vertical integration of a publicly owned solution.
To achieve this, it proposes three core policy recommendations:
Develop and/or strengthen fully open source models and the broader open source ecosystem
Provide public compute infrastructure to support the development and use of open models
Scale investments in AI capabilities to ensure that sufficient talent is developing and adopting these models”
All these ideas seem pertinent to our open work. I also think Public AI gives users an opt-in option alternative to big tech. We should be thinking about how to have our work be Digital Public Goods.
Reciprocity remains an AI fatal flaw but there are options. How might all of us working in open education and open science pursue and shape these options?
AI Catharsis #5 - Collaborative open data set creation
One of the ways the open community can take action is around collaborative open data set creations as a form of Digital Public Goods.

Sunrise in Dew Drops on Spider Web by Matthew Paulson CC BY-NC-ND
A fascinating example is described in “Common Corpus: building AI as Commons” where Alek Tarkowski and Alicja Peszkowska share a profile of Pierre-Carl Langlais, a digital humanities researcher, Wikipedian, and a passionate advocate for open science. Pierre is also the co-founder of a French AI startup, Pleias, and the coordinator of Common Corpus, a public domain dataset for training LLMs.
They note:
“As the largest training data set for language models based on open content to date, Common Corpus is built with open data, including administrative data as well as cultural and open-science resources – like CC-licensed YouTube videos, 21 million digitized newspapers, and millions of books, among others. With 180 billion words, it is currently the largest English-speaking data set, but it is also multilingual and leads in terms of open data sets in French (110 billion words), German (30 billion words), Spanish, Dutch, and Italian.
Developing Common Corpus was an international effort involving a spectrum of stakeholders from the French Ministry of Culture to digital heritage researchers and open science LLM community, including companies such as HuggingFace, Occiglot, Eleuther, and Nomic AI. The collaborative effort behind building the data set reflects a vision of fostering a culture of openness and accessibility in AI research. Releasing Common Corpus is an attempt at democratizing access to large, quality data sets, which can be used for LLM training.”
Openly licensed, peer-reviewed data is generally considered more valuable by AI developers and researchers due to its accessibility, transparency, and potential for reduced bias. It has been fascinating to watch Wikimedia devise its strategy for AI. They state:
“As the internet continues to change and the use of AI increases, we expect that the knowledge ecosystem will become increasingly polluted with low-quality content, misinformation, and disinformation. We hope that people will continue to care about high quality, verifiable knowledge and they will continue to seek the truth, and we are betting that they will want to rely on real people to be the arbiters of knowledge. Made by human volunteers, we believe that Wikipedia can be that backbone of truth that people will want to turn to, either on the Wikimedia projects or through third party reuse.”
The popularity of Wikipedia as a data source resulted in such an increase in traffic from AI data scrapers that performance was being jeopardized for regular users. This led them to create a set of enterprise grade APIs in Wikimedia Enterprise that provide access to datasets of Wikipedia and sister projects while being supported by robust contracts, expert services, and unwavering support. Wikimedia Enterprise is a paid service targeted at commercial users of Wikimedia. Christie Rixford notes:
“At first glance, this initiative seems to be mainly about securing new revenue sources and thus improving sustainability of this civic platform. But in reality it is a milestone in developing Wikimedia as an access to knowledge infrastructure, and a strategy for adjusting to ongoing changes in the online ecosystem.”
They go on to say:
“The case of the Enterprise API is fascinating, as it shifts focus from the most visible part of the Wikimedia project: the production of encyclopaedic content by the community of volunteers. Instead, it focuses on code and infrastructure as tools for increasing access to knowledge. In doing so, it shows the limits of enabling reuse solely through legal means.”
I think there are opportunities to create not just Large Language Models but smaller more customized openly licensed data sets for various academic domains using open science and open education sources. Higher education institutions or national systems could embark on the creation of specialized AI that starts with an existing open data set to which are added institution faculty endorsed open data sources and even student created open data, toward providing a unique and localized AI experience.
At the OEGlobal 2024 conference in Melbourne last year Martin Dougiamas proposed an OER Dataset for AI project.

Another good example is the Open Datasets Initiative which aims to curate high-fidelity AI ready open datasets in biology and the life sciences. You can imagine something similar for climate action and other specific areas such as the United Nations SDGs or other similar targeted goals.
Conclusion: Tragedy Foretold? or Tragedy Avoided?
I have argued that to date AI is a tragedy caused by five fatal flaws:
Tragedy of Capitalism over the Commons
Taking without consent
Demotivating sharing
Breaking reciprocity, and
Bleeding open dry
The fatal flaws conflict with the very things AI relies on risking an inevitable downfall of AI and associated downfall of open education, open science and other open practices.
I have also argued that the fatal flaws can be changed and suggested five ways the open community can take action to do so:
Social Agreements & Regulations
Preference Signals
Reciprocity
Public AI
Collaborative open data set creation
There are other AI flaws and options for action but these, I think, are the key ones. The extent to which AI really does end up being a tragedy or, alternatively, an important and thriving addition to open knowledge creation depends on our response to it.
I hope this post helps make the fatal flaws of AI visible and inspires action to resolve them in ways that contribute to a flourishing commons.
In the words of Anna Tumadóttir:
“When we talk about defending the commons, it involves sustaining them, growing them, and making sure that the social contract remains intact for future generations of humans. And for that to happen, it’s time for some reciprocity.”
Reimagining Open At The Crossroads
I’ve been deeply engaged in a couple of open education projects. In Europe I’m helping SPARC Europe with their Connecting the Worlds of Open Science and Open Education effort. In North America I’m helping the Open Education Network with a project to increase educational equity in higher education by developing models and guidance to help academic libraries formalize programs that support open education work at their institutions. Both projects are fascinating. I’m enjoying the teams involved and opportunities to dive deeply into these topics. I’m learning lots.
I’ve been quiet here with my blog. After last years intensive exploration of AI I took a pause. Over the course of my career I’ve been through many waves of technology aiming to enhance and disrupt education in positive ways. That trail is a long one with few successes and lots of failures well documented by Audrey Watters. AI feels like yet another over hyped technology that, so far at least, is over promising and under-delivering. AI seems not to have learned anything from the education technologies that came before it. I have little interest in furthering the AI hype cycle. However, I remain quietly interested in how AI is playing out in education, particularly open education.
The blog post I wrote on AI From An Open Perspective generated a lot of interest. But, recently I’ve found myself shifting to AI From a Commons Perspective. As I see it AI has appropriated a data commons with little to no regard for the commons or the norms associated with it. The sheer scale and blatant disregard is callous and yet another example of voracious capitalism exploiting a commons for profit. Not a good feeling if you work in the commons, your work is part of a commons, or you simply believe in the commons.
I was recently interviewed on the meaning of open artificial intelligence in education during which I suggested there is no “open” artificial intelligence in education. AI is not open. No matter what the companies say, or name themselves, the extent to which AI is “open” is limited. Even just what open means in the context of AI is being highly debated. (See here, here, here, here). I very much share the perspective of Luis Villa who both celebrates and mourns the data commons in his excellent My Commons Roller Coaster post. The lack of transparency and exploitive nature of current AI development is like a rotten apple at the bottom of the barrel. I find it hard to enjoy the fruit knowing what lies at the heart of it and the potential for full rot.
I’ve moved AI to the back burner - at least for now.
I moved Reimagining Open At The Crossroads to the front burner.
Garden Crossroads by Paul Stacey CC BY-SA
In March I attended the Association for Learning Technology (ALT) OER 2024 Conference in Cork Ireland. I found the keynote “The future isn’t what it used to be: Open education at a crossroads” delivered by Dr Catherine Cronin and Professor Laura Czerniewicz very thought provoking. The keynote was recorded and is available to watch on ALT’s YouTube channel. A keynote essay to accompany their keynote is available online here.
The keynote is divided into three sections: (I) The big picture, (II) Open education at a crossroads, and (III) Creating better futures. In their keynote Catherine and Laura issue a call to action and a framework for proceeding. After the conference I began to think it was possible to actually implement their call to action.
With Catherine and Laura’s encouragement I submitted a wild card proposal to the Open Education Global (OEGlobal) 2024 conference proposing a series of asynchronous online activities related to their call to action that I proposed take place during the weeks leading up the the OEGlobal 2024 conference in Brisbane. My proposal was accepted.
I devised a series of simple and fun activities which have launched in the OEGlobal 2024 Interaction Zone. There is an Introduction and a series of activities starting with Reimagining Open At The Crossroads Through Music.
Everyone is welcome to participate in these activities whether you are attending the OEGlobal 2024 conference or not.
The Reimagining Open at the Crossroads schedule of activities is:
Activity 1: Reimagining Open at the Crossroads Through Music October 14, 2024.
Activity 2: What if?, October 21, 2024.
Activity 3: Make Claims, October 28, 2024.
Activity 4: Pathways and Connections November 4, 2024. In person version will take place at the OEGlobal 2024 conference in Brisbane, Australia on Wednesday, November 13th from 10:30-11:30 am.
Activity 5: Pathway Sharing. Online and in-person pathway outputs from activity 4 are invited to be posted here in OEGlobal 2024 Connect. Making pathways visible makes it possible to connect with others who are following the same path, both those in person attending the conference and those participating virtually. Connections can be made simply by replying to a shared pathway, providing a link to your pathway, and identifying points of mutual interest.
Here is a short summary I wrote of the entire Reimagining Open At The Crossroads activity including some details from the in person Pathways and Connections activity in Brisbane. Huge thanks to everyone who participated.
AI, E-learning & Open Education
Yu-Lun Huang from National Yang Ming Chiao Tung University in Taiwan runs an e-learning movement project for the Ministry of Education in Taiwan. More than thirty universities in Taiwan participate in the project. One of the challenges they encounter is leveraging modern technology, like artificial intelligence, to improve digital learning or online education, especially learning effectiveness.
Yu-Lun's e-learning project hosted an E-learning and Open Education international conference on December 14, 2023 in Taiwan. Yu-Lun had read my AI From an Open Perspective post and kindly invited me to give an virtual keynote talk about AI for the conference and I accepted.
I titled my talk “AI, E-Learning and Open Education”.
I used a diagram of the AI technology stack to connect AI to e-learning and open education.

For each layer of the stack I identify challenges and opportunities associated with AI in education. For example at the Data layer:

Yu-Lun asked me to focus on how AI can improve digital learning and learning effectiveness. Toward that end I describe AI pedagogical uses:

I provide a few examples of education AI applications and tools including those for pedagogy, AI for subject specific use (history, biology, math, music, …), and AI integrations into learning management systems.



I talk about AI digital literacy including the importance of prompts.

I talk about cheating and plagiarism.

I close my talk with a call to action suggesting actions educators in Taiwan (and elsewhere) can take to understand AI and use it in their teaching and learning practice.

And finally I concluded my talk with a recommendation specific to Taiwan.
Taiwan has a reputation as a smart, innovative nation and is already a world-leader in the area of semiconductors, information and communication technology (ICT) and manufacturing. These strengths position it well to build on and advance AI.
Taiwan came up with an AI strategy relatively early. Starting in 2017 it began making major investments in AI development. The Executive Yuan published a 4-year AI Action Plan with a budget of 38 billion NTD (1.1 billion EUR) and the Ministry of Science and Technology (MoST) published a 5-year AI Strategy with a budget of 16 billion NTD (490 million EUR). These initiatives were largely focused on economic matters including:
creating a national AI cloud service and high-speed computing platform
nurturing AI research service companies to form a regional AI innovation ecosystem
publishing open data
building AI innovation research centers to train AI specialists, invest in technological development, and expand the pool of AI talent
establishing an AI Robot Makerspace for innovative applications and integration of robotics software and hardware
encouraging AI start-ups including available start-up accelerators and incubators supported by multinationals such as Google, Microsoft and IBM
As a final recommendation I advocated for Taiwan to similarly invest in, align, and expand its strategy to include AI in education.

The talk was not recorded and I know it’s hard to get the full picture without accompanying narration but here is a link to my AI, E-Learning and Open Education slides. Many of the slides have links which are clickable in Slideshow view.
AI is changing fast so this is really a snapshot in time but I hope it is useful to educators in Taiwan and around the world. Big thanks to Yu-Lun for the invitation.
I enjoy dialogue about all things I post. Every post has a corresponding discussion forum on OEGlobal Connect. If you want to connect you’ll find me there. I welcome AI, E-Learning and Open Education discussion there.
AI, Creators and the Commons
On October 2nd, the day before the Creative Commons (CC) Global Summit in Mexico City began, OpenFuture and Creative Commons hosted an all day workshop on “AI, Creators and the Commons”.
The goal of this workshop, organized as a side event to the CC Summit, was to understand and explore the impact of generative machine learning (ML) on creative practices and the commons, and to the mission of Creative Commons in particular.
The workshop brought together members of the Creative Commons global network with expertise in copyright law, CC licenses as legal tools, and issues in generative AI, in order to develop an understanding of these issues, as they play out across different jurisdictions around the world.
The workshop focused on the "input" side of generative AI particularly on the data used to train ML. The morning session focused on:
How do copyright systems around the world deal with the use of copyrighted works for training generative ML models?
The aim was to understand whether there are differences between jurisdictions that affect whether, and how copyright protected works (including CC licensed works) can be used for AI training. Questions asked included:
Are there differences between jurisdictions that affect whether, and how copyright protected works (including CC licensed works) can be used for AI training?
How do different legal frameworks deal with this issue and what balance do they strike?
What are the implications for creators?
What are the implications for using open licenses?
Here are a few of my takeaways and responses to those questions from this session.
In the USA two areas of copyright activity related to AI are copyright over AI outputs and copyright related to inputs used for AI training.
The legal case around the comic book Zaraya of the Dawn was used as an example of copyright related to AI outputs. Although originally granted full copyright that was subsequently revoked. Instead, the text as well as the selection, coordination, and arrangement of the work’s written and visual elements were granted copyright but the images in the work, generated by Midjourney, were not as they were deemed '“not the product of human authorship”.
A relationship between a creators use of AI technology and a creators use of photography related tools was made. In taking a shot a photographer engages in composition, timing, lighting, and setting. After taking a shot they engage in things like post editing, combining images, and final form. In photography copyright is assigned to the person who shoots or takes the shot. In what way is use of AI technology different?
Pertaining to issues related to copyright of inputs used for AI training, reference was made to the many class action legal cases that are underway contesting that use of copyrighted works to train AI constitutes copyright infringement.
The legal case around Getty Images suing AI art generator Stable Diffusion in the US for copyright infringement was used as an example. Getty has licensed its images and metadata to other AI art generators, but claims that Stability AI willfully scraped its images without permission. This claim is substantiated by Stable Diffusion recreating the Getty company’s watermark in some of its output images. This case is interesting for the way it attests copyright infringement but also manipulation of copyright data (the watermark).
Another example was the Authors Guild’s class action suit against OpenAI. This complaint draws attention to the fact that the plaintiffs’ books were downloaded from pirate ebook repositories and used to train ChatGPT. from which OpenAI expects to earn billions. The class action asserts that this threatens the role and livelihood of writers as a whole and seeks a settlement that gives authors choice and a reasonable licensing fee related to use of their copyrighted works.
US defendants in these cases are expected to argue that their use of these works to train their AI is allowed under “fair use”. From a copyright perspective Generative AI is particularly disruptive because outputs are not exactly similar to inputs. But a key question will be whether they are similar enough. Do they demonstrate high transformativity?
Some artists are suing based on principle. Some see AI competing with them unfairly. Some are concerned about AI replacing human labour. And still others see AI created works as a violation of their integrity and reputation.
Canada, Australia, New Zealand, Japan and the UK all have something called fair dealing which is similar to the US fair use. So in these jurisdictions AI use of copyrighted works are expected to argue fair dealing allows them to do what they are doing.
In addition to fair dealing, some jurisdictions have copyright exceptions that allow for text and data mining. Text and data mining is an automated process that analyzes massive amounts of text and data in digital form in order to discover new knowledge through patterns, trends and correlations. Initial efforts to establish text and data mining were done largely in the context of supporting research. Creators and general rights holders did not pay much attention to it. But now, with generative AI, text and data mining is affecting everyone. Text and data mining exceptions, where they exist, present another means by which AI tech companies can argue they are legally allowed to do what they do.
In 2016, Japan identified AI as one of the most important technological foundations for establishing a supersmart society they call Society 5.0. In 2017 they amended copyright legislation to allow text and data mining classifying the activities into four categories, (1) extraction, (2) comparison, (3) classification, or (4) other statistical analysis. The Japanese exception is regarded as the broadest text and data exception in the world because: (1) it applies to both commercial and noncommercial purposes; (2) it applies to any exploitation regardless of the rightholders reservations; (3) exploitation by any means is permitted; and (4) no lawful access is required.
Other countries such as Singapore, South Korea and Taiwan have adopted similar rules with the intention of removing uncertainties for their tech industries and positioning themselves in the AI race, unencumbered.
EU's Directive on Copyright in the Digital Single Market, adopted in 2019 introduced two text and data mining exceptions. One exception is for scientific research and cultural heritage with a caveat that use be non-commercial. The second is a more general purpose exception which allows commercial use as long as source data is lawfully accessed and creators have the option to opt out. This general purpose exception is seen as the one applicable to generative AI.
Opting out is seen as giving a creator leverage and the first step in securing a licensing deal. The opt-out requirement is seen as extremely difficult to implement at a practical level. At this time creators have no idea whether their works are being used by AI and AI tech players are not disclosing what data is being used to train their models. In some cases there may be multiple copies of works and there is no simple way of ensuring all copies of your work have been excluded. In addition it is not clear whether opt-out only applies to new uses or whether it is retroactive. How does opt out affect AI models that already include your work? Opt out is also seen as unfair to those who have passed away. They can't say no to their work being used by AI. Massive opt out may result in even greater bias being present in AI models.
There is a big challenge around ensuring opt out is respected. Early attempts to enable opt out such as those from ArtStation are seen as cumbersome difficult to enforce and placing a large part of the onus on the creator. Complex opt out systems will favour large players who are the biggest rights holders. Copyright holders are often not the creator themselves but large publishers or intermediaries who have acquired the rights to those works. Opt out needs to be simple enough that anyone can do it. There are some who don’t want opt out but instead a mandatory compensation.
An Africa perspective is one of being left behind and upending livelihoods. Big tech AI and transnationals have created a problem through their use of data sourced in Africa without collaboration or recognition of local communities. But what to do? The data is already taken.
Financing of AI research and use of data is all global north. AI is data colonization and a threat to sovereignty. Local languages in training AI are absent. Creators are facing realization that they can be replaced. Text and data mining was thought of as something for scientists and analyzing literature to get insights. Now there is a growing realization that text and data mining touches everyone. Does text and data mining, fair use / fair dealing really allow use of everything?
There is interest in creating a licensing market. But copyright is not and never has been a good or effective jobs program. Copyright has done a poor job of benefiting creators to generate a living. Copyright is wielded by a few big players to benefit a few. Want creators fairly rewarded and remunerated.
Kenyan workers cleaning AI data is unethical - not a copyright issue. Need to go beyond copyright and address labour issues.
Are we entering a knowledge renaissance? Or a desert where sharing is not allowed? Are countries taking a 21st century lens going to allow anything?
Latin America does not have copyright exceptions with a big enough scope to enable AI. They do not have fair use or text and data mining exceptions. Lack of these copyright exceptions is not really a current issue. Data privacy is the more pressing issue. Health data is an area of focus along with open science discussions on who owns data.
Renumeration tends to go not to the creator but to large rights holders. Desire to see creator right to renumeration against big platforms including but going beyond AI.
It is difficult for a country to figure out how to enter the AI field.
AI is data colonization. AI is extracting local community data and using it for commercial purposes. Local community data is communal not individual. It should not be used without local community permission. Western civilization notions like copyright are counter to traditional knowledge.
This session generated a lot of observations and questions for me:
Creators push for copyright because it is the only tool they have. What are other strategies?
Current copyright law is deficient in being able to handle all these AI issues. Ensuring an ethical, responsible and fair for all AI will require going beyond copyright law.
Data “mining” sounds like exploitation.
Rights holders want consent, credit, and compensation.
Opting out of something is different from opting in to something. What alternative to big tech AI can creators and AI users opt in to?
What is the commons? Are differentiations such as public domain, commons licensed, copyrighted still relevant? Is the entire Internet just a big commons database available for AI to freely scrape and use?
ML Training and Creators
This moderated group discussion after lunch focused on understanding the position of creators in relation to generative ML systems. What are the threats and opportunities for them? To what extent do creators have agency in determining how their work can or should be used? What tools (legal and/or technical) are available to creators to manage how their works can or should be used? How do CC licences fit into this, and is there a need for CC to adapt or expand the range of tools that it provides to creators?
Here are some of my points of learning and takeaways:
Law is slower than technology.
Creative Commons tools have reduced relevance in the context of generative AI. The way Creative Commons licenses involve attribution, giving back to the community, and creating a commons has been disrupted by AI. The original idea around Creative Commons was to give creators choice. How does Creative Commons support creator choice in the context of AI?
In the context of generative AI users are not just traditional creators but business enterprises, educators, biotech and health care. In what way are Creative Commons licenses useful to these new users?
Creative Commons has played a key historical role in the ethics of consent, expression of preferences, and norms around responsible use. In the context of AI how can CC continue with these roles? Perhaps there is a role around commons based models, commons based open outputs, and AI for the public good?
Generative AI represents a fundamental breaking of the reciprocity of the commons. It has spawned a lack of trust in copyright. AI needs to restore trust associated with data.
AI creates a different power structure. It breaks the social compact of the commons. Many rights holders have become overtly hostile to the commons. Opting out is in some ways an expression of “you can’t learn from me”, an undesirable outcome. One way some trust could be restored is if AI models were by default in the commons. This would restore some balance and giving back.
AI companies still don’t have a business model. The traditional big platform model of selling ads seems inappropriate. AI needs a model that does not give big tech disproportionate benefit.
We need a legal technical innovation (other than copyright) that builds a shared culture where we can all participate. We need a more global AI approach. We don’t have to be western to be modern. What we really need is guardianship not ownership. A means of connecting to one another across national boundaries. AI needs a set of principles and values shared across cultures. We need to give people agency back.
Creative Commons licensing is not a way to accomplish this. But, if it is not licensing then what?
ML Training and the Commons
This final session of the day moderated group discussion continued exploration of the relationship between generative ML and the commons. Questions posed included; How do generative ML models impact the commons? How important are the commons when it comes to ML training? How can we best manage the digital commons in the face of generative ML? How do traditional approaches to protecting the commons from appropriation, such as copyleft and share alike, interact with generative ML?
My note taking diminished this late in the day but here are a brief few points of interest that came up for me:
Creative Commons what are you going to do about AI?, is a question CC is hearing loud and clear.
Creative Commons is certainly about licenses, but not solely. CC is about reducing legal barriers to sharing and creativity. It’s not just about copyright, it’s about growing the commons.
CC tools should never overrule exceptions and limitations.
Copyright is not the best tool for resolving AI issues. CC licenses have held up well over time but other big issues have surfaced. What is legal vs what is not? What is right vs wrong? Calls for a code of ethics, community guidelines and social policies.
In creating new works AI could empower creators not betray them. AI’s unwillingness to cite sources and identify where data comes from is not helping.
Better sharing is sharing in the public interest.
AI could broaden the commons.
Is AI a wonder of the world?
Closing Thoughts
I found this day very thought provoking. This blog is by no means a complete comprehensive summary, merely things I took note of throughout the day.
Kudos to OpenFuture and Creative Commons for co-hosting this day and to all the participants for actively sharing their perspectives, experiences, and advice. I’m especially impressed with CC’s willingness to ask these hard questions and engage in self critique while at the same time actively seeking to define it’s position and role in generative AI and the commons going forward.
I appreciate being invited to this session and participating as a vocal active contributor. It helped develop a common understanding and generated observations, questions and discussion that carried forward into the follow-on three days of Creative Commons Global Summit.
I’m a strong advocate for being proactive in defining the future we want. As part of my participation in this workshop I mentioned being in a position to comment on and make recommendations related to Canada’s draft AI Act. I expressed interest in developing a shared collective position of principles, ideas and values that we could bring forward as part of an effort to shape AI legislation in all our respective countries right from the start.
I was thrilled when Paul Keller ran with this idea and over the ensuing three days of the Summit worked with a group of contributors to develop a statement on Making AI Work For Creators and the Commons.
When I returned home to Canada I did submit a briefing note of comments and recommendations on Canada’s AI Act and was delighted to reference and include the text of the Making AI Work For Creators and the Commons in my statement. My blog Policy Recommendations for Canada’s AI Act provides context and my full response.
I've created an AI, Creators and the Commons discussion topic in OEGlobal's Connect space. If you have thoughts or ideas on any of this I welcome discussion and suggestions there.
Policy Recommendations for Canada’s AI Act
After writing AI From An Open Perspective I became interested in the status of AI regulation in Canada, where I live. I learned that a Parliamentary Caucus on Emerging Technologies made up of a cross-partisan working group of Canadian Parliamentarians has been convened in response to the rapidly changing technology landscape that presents both opportunities and challenges for Canada. As it notes on their web site:
“The Caucus has been formed in recognition of the fact that in many cases, emerging technologies change and are deployed faster than the speed of government, sometimes to the detriment of economic growth and public health and safety.
The Caucus aims to function as a nimble forum to link Parliamentarians with a broad range of stakeholders engaged in relevant fields (e.g. artificial intelligence, web3 and blockchain technologies, etc) in order to educate, and where possible, build consensus on principles related to the role of government in these areas in order to see positive outcomes for Canadians.”
I learned that the caucus would be spending the summer getting up to speed on AI so I reached out to one of the co-chairs, the Honourable Michelle Rempel Garner, PC, MP inviting caucus members to read AI From An Open Perspective as part of their summer reading.
Some weeks later I heard back from Michelle’s policy advisor who thanked me for my email, shared with me the Parliamentary Caucus September 2023 report, and invited me to connect for further discussion via a phone call. We had a great conversation and a few days later I received an invitation to submit a written brief to Parliament’s Standing Committee on Industry and Technology which had just begun its examination of Bill C-27 which includes the draft Artificial Intelligence and Data Act (AIDA). I promised to submit a written brief after attending the Creative Commons Global Summit on AI and the Commons in Mexico City, October 2-6, 2023.
The Summit contributed significantly to further motivating me to submit a brief and helped generate clarity and substance for what my briefing should say. I submitted a briefing note on October 24, 2023 with five recommendations:
Revise the AI and Data Act based on principles that protect the rights of creators, people building on the commons, and society’s interests in sustaining the commons.
Encourage use of open as a means of establishing AI ethical and responsible values, ensuring transparency, creating public good, stimulating AI innovation, mitigating risk, and generating new business models.
Invest in AI open infrastructure to ensure public utility, support of research, and small to medium enterprise innovation.
Consider a social contract requiring any commercial deployment of generative AI systems trained on large amounts of publicly available content to pay a levy.
Create an AI Constitution that lays out the values and ethics Canada seeks to ensure are part of responsible AI development and use. And establish an AI International Governing Body to ensure national regulations are harmonized and work collaboratively with other nations to reduce risks and enhance benefits.
You can read the full text of my briefing note here. It is currently being translated into French, shared with members of the committee, and posted to the committee’s website.
This is the first time I’ve ever submitted recommendations on draft legislation. I encourage any of you who are similarly interested to do so. It feels empowering to proactively try and shape the future of AI in this way.
Special thanks to OpenFuture for all they’ve been doing in the area of open and AI. Many of my recommendations are directly based on their work.
Sustainability Models
SPARC Europe Open Education Cafe
I’m looking forward to being a panel speaker at SPARC Europe’s Open Education Cafe on October 10, 2023 at 7am Pacific Time . This, the fifth in a series of open education cafe’s SPARC Europe has arranged around the UNESCO Recommendation on Open Educational Resources (OER), is focusing on the Recommendation’s fourth action area “nurturing the creation of sustainability models for OER”.
There is a huge need for easy to understand and replicable OER sustainability models and I am super interested in this topic so I am thankful to be part of this panel. Special thanks to Paola Corti for organizing this Cafe and inviting me to speak.
UNESCO OER Recommendation
I had the good fortune to contribute to the writing of the sustainability text used in the UNESCO Recommendation which defines steps to take in creating a sustainability model including:
reviewing current provisions, procurement policies and regulations to expand and simplify the process of procuring quality goods and services to facilitate the creation, ownership, translation, adaptation, curation, sharing, archiving and preservation of OER, where appropriate, as well as to develop the capacity of all OER stakeholders to participate in these activities
catalyzing sustainability models, not only through traditional funding sources, but also through non-traditional reciprocity-based resource mobilization, through partnerships, networking, and revenue generation such as donations, memberships, pay what you want, and crowdfunding that may provide revenues and sustainability to OER provision while ensuring that costs for accessing essential materials for teaching and learning are not shifted to individual educators or students
promoting and raising awareness of other value-added models using OER across institutions and countries where the focus is on participation, co-creation, generating value collectively, community partnerships, spurring innovation, and bringing people together for a common cause
enacting regulatory frameworks that support the development of OER products and related services that align with national and international standards as well as the interest and values of the OER stakeholders
fostering the faithful linguistic translation of open licenses as defined in this Recommendation to ensure their proper implementation
providing mechanisms for the implementation and application of OER, as well as encouraging the feedback from stakeholders and constant improvement of OER; and
optimizing existing education and research budgets and funds efficiently to source, develop and - continuously improve OER models through inter-institutional, national, regional and international collaborations.
The Recommendation does a good job of identifying the scope of considerations that should factor into a sustainability model. But it does not provide actual examples. You must devise your own. For those wanting to ensure their OER has a sustainability model this can be a barrier.
OER Sustainability Models Literature
Fortunately there is a growing body of literature on this topic including:
Konkol, Markus, Jager-Ringoir, Katinka, & Zurita-Milla, Raúl. (2021). Open Educational Resources – Basic concepts, challenges, and business models (2.0). Zenodo. https://doi.org/10.5281/zenodo.4789124
This study puts forward the following models as relevant:
Selling course experience model
Governmental model
Institutional model
Online programme model
Substitution model
Community-based model
Donations model
Institutional subscriptions model
Sponsorship/advertising model
Membership model
Selling data model
Consultancy, training and support model
Author pays model
Tlili, A., Nascimbeni, F., Burgos, D., Zhang, X., Huang, R., & Chang, T. W. (2020). The evolution of sustainability models for Open Educational Resources: insights from the literature and experts. Interactive Learning Environments, 1-16. http://sli.bnu.edu.cn/uploads/soft/201124/2_2014185631.pdf
This study identies the following potential OER sustainability models that can be implemented in contemporary higher education systems:
Through public funding
Through internal funding
Through endowments/donations
By participating in an OER network
By offering services to learners
By relying on OER authors
Community-based model
By producing OER on demand
Through sponsorship/advertisement
By offering learning-related data to companies
Both studies emphasize that in practice OER initiatives use combinations of models.
Rob Farrow, as part of the European Network for Catalysing Open Resources in Education (ENCORE+) is doing some good work analysing all these models. See OER Sustainability Business Models and A Typology of OER Business Models.
I find it helpful to define models in this way, including the related details associated with each. But I also find it lacking.
Models Critique
OER are not just educational resources, they are “open” educational resources. Sustaining the open part of OER is essential but missing from these models. The practice of open must be embedded in any OER sustainability model.
A sustainability model is not the same as a financial model. Most of the example models focus on financial issues. While financial considerations are certainly part of a sustainability model they are not the whole thing. Furthermore the example models focus on revenue without considering costs. Many of the financial models are simple means of generating revenue lifts from traditional business models and do not map well to education and the way it is funded. These models do not fully take into account how the economics of open are different than non-open, and the way open changes not just the financial model for education but its very practice.
These models do not address the full life cycle of OER - from creation, to use, to storage and distribution, to maintenance and enhancement. A sustainability model must factor in the full life cycle and the stewarding required for persistence and longevity. OER are like living things requiring ongoing care and sustenance. These existing models say little about the means by which this will be done. A sustainability model ought to make explicit the way OER involves collaborating with others to generate, maintain and steward something of mutual value.
And finally these models miss the larger context of value. Access, inclusion, adaptability, and quality are but a few of the ways OER improve the value proposition of education. The models are silent on value or assume parity of value between OER and more traditional closed education resources. An OER sustainability model ought to take into account the value OER generates in uniquely making it possible to fulfill visions, goals and diverse purposes of education.
In this blog post, and for the SPARC Europe Open Education Cafe, I’m going to bring forward these and other missing considerations. I aim to establish them as essential foundational building blocks. And I’ll share a few example OER sustainability models of my own that start from that foundation.
Devising A Sustainability Formula
Over a two year period from 2015 to 2017 I co-authored with Sarah Hinchliff Pearson a Kickstarter funded book called Made With Creative Commons.

This book describes how open makes sense as a model for organizations. It analyzes open business models and provides profiles of twenty four organizations, across all sectors, who have devised sustainable models.
In the years since that book came out many have expressed interest in adopting an open model but have asked me for guidance on just how to do so. In some ways the twenty four case studies in the book are all unique. There is no one size fits all model. Nonetheless I felt compelled to distill out of everything in Made With Creative Commons some core pithy advice that would apply to everyone no matter what sector you are in or the specifics of the model you are pursuing. In the end I came up with a simple formula:

Sustainability = high value open resources + public social good + large community of users, partners, collaborators
Lets look at each variable in the formula.
For you to have a sustainable open model you must produce high value open resources. If you are simply sharing some low value thing openly the likelihood of creating a sustainable model is low. The higher the value proposition of the open resource the higher the likelihood of a sustainable model. An essential element of that value must be some kind of public social good the resources generate. It helps if your organization has a social mission not just ambitions for profit, investor returns, and unlimited growth. If you have a high value open resource that generates some kind of public social good others will use it and join you in enhancing it. Building a large community of users, collaborators, and partners is essential. If you have all three of those things then you have the foundation for a sustainable open model.
This simple formula asserts that sustainability involves combining resources that generate social good with human connection. Organizations that pursue this strategy aim to provide value and build relationship up front. Once those are in place there can be reciprocal value creation between all involved out of which a sustainable model emerges.
This formula for me is a test for sustainable models. I ask myself are there high value open resources being shared? Do those resources generate significant public social good? Is there a large community of users, collaborators and partners working with the resources? If the answer is yes to all three then things are looking good for creating a sustainability model. If the answer is no to one or more of these variables then work needs to be done to convert the no’s into yes’s before a sustainability model can be devised.
When you apply this test to the models described in the literature the models appear even more inadequate.
National OER Framework Sustainability Model
By now you’re probably saying OK show me an example. So let me share an OER sustainability model I presented at a workshop I gave at the National Center for e-Learning Ministry of Education, in Riyadh, Saudi Arabia back in October-2014. At the time I was part of an initiative called the Open Book project which Hillary Clinton started when she was US Secretary of State. The goals of the Open Book project were to:
Deliver the benefits of open education to the Arab world
Expand access to free, high-quality, open education materials in Arabic, with a focus on science and technology
Implement open licensing in the MENA region that enables anyone to use, adapt, and share these education materials
Build partnerships between the US and MENA region to make more learning materials open, free, and connected to Arab educators, students, and classrooms
Lower geographic, economic, and even gender-based barriers to learning
Create open education resources that anyone with access to the Internet can read, download, and print for free or adapt a copy that meets the local needs of their classrooms or education systems.
Put a full year of high-quality college-level science textbooks – biology, chemistry, physics, and calculus – online, for free, in Arabic
Help Arab professors and intellectuals create their own open courses
Explore the benefits of OER for governments, institutions, faculty, students and the public, specifically examining how OER affects teaching and learning practices including the inter-relationships and synergy of OER with open access, open data, open policy, open science
Evaluate the impact of OER
The Open Education Consortium, Creative Commons and World Learning were asked to organize and run the initiative. Participants from across the Middle East and North Africa (MENA) region took part in a kind of fellowship, mentoring learning exchange including time onsite with a range of OER initiatives across the USA. On their return home they were tasked with starting their own OER initiatives.
As the Creative Commons lead on this project I took part in site visits across the MENA region to see how progress on OER was going, providing assistance with planning and implementation, and making recommendations in support of enhancing progress and impact. In Riyadh I was asked to present a national OER framework for planning and implementing OER. Here is the one pager I generated which I share as an example of a national OER sustainability model:

When it comes to OER I usually get a lot of questions related to technology. However, in this diagram I try and show that there are many components to an OER initiative that have nothing to do with technology and come well before technology decisions need to be made.
I start with Strategy. Large-scale OER initiatives should be strategic and purposeful. Doing OER without a real purpose is not a recipe for success. The US Department of Labor TAACCCT program is a great example of a national OER initiative with a clear purpose – move displaced and unemployed workers into jobs in high growth industry sectors by funding community colleges to create stacked and latticed credentials in partnership with industry. All the curricula these community colleges create must be licensed with a Creative Commons CC BY license making them OER.
In addition to strategy a large OER initiative needs incentives which could be monetary or could be other things related to innovation or transformation of teaching and learning.
A national OER framework should include a research component. It is essential to test out the strategy and purpose of any OER initiative and evaluate practices and outcomes on an ongoing basis. Research informs success. I point to a current source of OER research – the OER Research Hub (and in subsequent versions of the diagram have included the OER Knowledge Cloud).
To enable large scale success OER require policy. There are a number of guidelines available for generating policy including:
Atenas, Javiera; Havemann, Leo; Neumann, Jan; Stefanelli, Cristina (2020). Open Education Policies: Guidelines for co-creation.
Miao, Fengchun, Mishra, Sanjaya, Orr, Dominic, Janssen (2019). Guidelines on the development of open educational resources policies
Strategic purpose, incentives, research, and policy all impact the activities of institutions. A national OER initiative involves many institutions. Two institutional practices I’ve come to see as critical to success are:
Forming inter-disciplinary OER teams within an institution made up of faculty, instructional designers, media producers, librarians, and educational technologists. For OER to succeed a team effort is needed and each of these roles has crucial skills and knowledge to contribute. Faculty have the subject matter expertise, instructional designers the ability to design effective teaching and learning structures and activities, media producers can produce rich multimedia, librarians are superb at finding and curating collections, and educational technologists bring essential skills about how best to develop and deliver OER with technology.
Forming communities of practice across all the institutions involved in a national OER initiative that bring together people across institutions by domain (such as arts, science, engineering, etc.) and by role (such as faculty, instructional designers, librarians, etc.) All distinct fields of study and members of OER teams like to talk to their peers at other institutions. The challenges tend to be the same and they frequently learn about great resources their peers have found or new practices that are working well.
For actual OER content I advocate implementation pursue four distinct efforts. First review existing curricula already developed and in use that could simply be openly licensed and made in to OER. Second identify educational content that is desired and search existing OER to see if anything is available. If it is simply adopt it. Sometimes OER is found but is not a perfect fit. If that is the case why not adapt it – translate, localize, customize, update or improve the educational materials so that the fit works. Thats one of the benefits of OER – you can modify it. Finally, as a last measure, having exhausted the previous three efforts if OER is needed where none exists then go ahead and author it.
OER is transforming education by making educational materials visible and available to all. Success is contingent on high quality resources. In higher education research is quality assured through peer review. I believe the same practice is a success factor for OER too. OER should be vetted through a quality review process and peer review.
I place technology next well after all those other key success factors have been dealt with. I highlight a few of the key technology components in the diagram – authoring tools, open file formats (so others can modify the resource downstream), creating portable interoperable content that can be exported out of one Learning Management System and uploaded to another, classification schema for OER, and repositories or referatories where OER can be found, previewed, and downloaded.
Finally we come to usage. OER are multi-use. They can be used in on campus courses, mixed or blended courses, fully online courses, and MOOCs. OER don’t just have teaching and learning value they are useful as a means of marketing to students (try before you buy), they provide a rich source of supplemental resources for students to use when they are studying, they can help industry meet the professional development needs of their employees, they help working adults pursue career pathways, and they attract national and international interest in your institution.
In subsequent versions of this diagram I’ve added accessibility (ensuring OER meet the needs of those less abled) and pedagogy (factoring pedagogical approaches into the design of OER and innovating new open pedagogies based on the unique attributes OER have).
This National OER Framework sustainability model emphasizes a system wide collaboration effort, development of educational resources that have collective value, and the unique ways open practices can enhance education. It fulfills all three variables in my sustainability formula.
Open Operating System Sustainability Model
Another lesson I learned from writing all the case studies in Made With Creative Commons is the importance of considering all aspects of an organizations operations through an open lens. Let me give an example based on one of the case studies in Made With Creative Commons. While not an education initiative this case study illustrates the process of centering open as key to your operations. Let me briefly describe it and then come back to show how the process they used could be applied to education and create an open sustainability model.
Opendesk is an online marketplace that hosts independently designed furniture and connects its customers to local makers around the world. Rather than mass manufacturing and shipping worldwide, they’re building a distributed and ethical supply chain through a global maker network.
The typical business activities associated with manufacturing furniture look something like this:

Opendesk looked at each of these activities through an open lens. In doing so they totally changed the business model associated with furniture. Here’s how their model looks mapped to each of these business activities:

Instead of having their own internal team doing research and development associated with designing and manufacturing furniture they invited furniture designers from around the world to provide them with designs. This allows them to source and curate designs that go well beyond what they might have come up with internally. Designers are asked to openly license their designs by choosing from the full suite of Creative Commons licenses, deciding for themselves how open or closed they want to be. Most chose the Attribution-NonCommercial license (CC BY-NC). Anyone can download a design and make it themselves. But most people don’t have the knowledge or equipment to do so and instead of making the furniture themselves they buy it from Opendesk who connects them to a registered maker in Opendesk’s network, for on-demand personal fabrication in close proximity to where the customer lives.
Instead of having their own factory for manufacturing and assembling the furniture Opendesk uses a network of makers around the world who do digital fabrication based on the designs using a computer-controlled CNC (Computer Numeric Control) machining device. This tool cuts shapes out of wooden sheets according to the specifications in the design file.
For sales, marketing, and business development Opendesk created a web platform matching customers to designs and local makers. With manufacturing done by local makers there is no need to store furniture in a warehouse or provide shipping and delivery. Customer service and support is done as a partnership between Opendesk and local makers.
The Opendesk financial model ensures that designers, makers and Opendesk itself get a fair share of the sale. For more details on how finances are done I encourage you to read the case study in Made With Creative Commons.
Opendesk describes what they do as “open making”. Designers get a global distribution channel. Makers get profitable jobs and new customers. Customers get designer products without the designer price tag, a more social, eco-friendly alternative to mass-production and an affordable way to buy custom-made products.
The Opendesk case study is an example of how adopting open as an operating system and examining all facets of the business through that lens can lead to a new way of doing things and a sustainability model different from current practice.
Applying the open operating system model to OER entails examining all education operational processes through the lens of open. Doing so will lead to new OER sustainability models.
Currently most OER initiatives are done as projects with one time funding and fixed start and end dates. Done this way OER is an incremental add-on to existing operational processes. While some of the benefits of open can be attained in this way, it is slow, limits the full value proposition of open, and curtails innovation as the new open practices are forced to meld with existing operational systems and practices that are often not aligned with open. When OER are short term projects, done on the side, without affecting existing operations there is no long term sustainability model. A sustainability model requires positioning open to be core to institution operations.
Devising a sustainable model just around OER fails to take into account the broader context of open. Open practices in education extend well beyond OER to include Open Access, Open Science, Open Data, and open source. Strategically bringing these various forms of open together acknowledges and strengthens their shared purpose and practice. The aggregate whole of all these forms of open is greater than the sum of their parts. A comprehensive open operating system approach that includes all these forms of open generates a stronger more synergistic sustainability model rather than one limited only to OER.
Consolidating the various forms of open increases all the variables in my sustainability formula. Collectively there is a larger value proposition, the social good being generated is larger, and the total number of users, participants, partners, and collaborators increases.
Situating open as an operating system involves positioning open as central to operations and showing how all these forms of open align with, and strengthen, the mission, strategy, policy and success metrics of the organization.
Operationalizing open as an operating system involves using open as a lens to evaluate all other operational processes. Education operational processes differ from the manufacturing processes associated with the Opendesk example. Instead of R&D, manufacturing, marketing and sales, distribution and delivery, and customer support education has teaching, learning, research, academic program of studies planning and development, student services, enrolment, procurement, finance and administration, alumni relations, marketing and communications, information technology and so on. To develop a fully robust sustainability model requires examining how open changes these operations.
Here is a diagram depicting the Open Operating System Sustainability Model.

Global Commons Sustainability Model
OER by their very nature are global public goods. Yet current sustainability models do not consider their global nature. A global commons sustainability model works toward fulfilling education as a basic human right and brings together all education providers in a collective effort to make education available as a global public commons.
Such a model may seem a pipe dream but the Gateways to Public Digital Learning global initiative led by UNESCO and UNICEF comes pretty close. Here is how this initiative is described:
“The aim is to help countries recognize and act on national, regional, and global possibilities to advance education through digital cooperation and solidarity. The internet allows unprecedented possibilities for sharing, cooperation, and the pooling of resources that can benefit learners, teachers, and families within countries and across them. This initiative seeks to maximize these collaborative actions.”
The Gateways initiative focuses on digital learning content noting; “During the COVID-19 pandemic and to this day, many people who have good connectivity and strong digital skills cannot find free, well-organized and high-quality digital learning content aligned with the curriculum. This content helps strengthen the other keys to digital learning: easily accessible digital learning content bolsters demand for connectivity and helps people develop and improve digital capacities.”
In addition to content, the initiative aims to work with countries to establish and enrich public platforms for education on the internet. The aim is to ensure learners, teachers, and families can access a wide range of learning resources from digital platforms that are public, open, and well-maintained.
Current efforts are focused on two important commitments that emerged during the recent Transforming Education Summit:
Establish and iteratively improve national digital learning platforms with high quality, curriculum-aligned education resources, ensuring they are free, open and accessible for all, in line with UNESCO’s Recommendation on Open Educational Resources, and respect the diversity of languages and learning approaches, while also ensuring the privacy and data security of users.
Ensure these platforms empower teachers, learners, and families, support accessibility and sharing of content, and meet the diverse needs of users including learners with disabilities, girls and women, and people on the move.
It’s great to see incorporation of the UNESCO Recommendation on Open Educational Resources in this effort.
An effort to collaborate on generating a global collection of OER aligned to curriculum, in different languages, supporting accessibility and inclusiveness, with different learning approaches is a pretty big value proposition with a large public social good. The extent to which different countries can rally their schools and institutions to participate is the sustainability variable that will require most attention as it is essential to create a large number of users, partners and collaborators.
Toward that end countries are invited to join the initiative by becoming a "Gateways Country” forming a networked community of practice around this effort.
Here is a diagram depicting the Gateways to Public Digital Learning as a global commons sustainability model:

I’m not sure if the Gateways to Public Digital Learning initiative sees itself as a global commons or as having a sustainability model. But I do.
Design Your Own Model
I have presented three sustainability models:
National OER Framework
Open Operating System
Global Commons
In designing these models I gave consideration to the following that you might find useful in your own model design efforts:
Each model implements UNESCO OER Recommendation steps for creating a sustainability model, but in different ways. Many sustainability models are possible. These are but three examples. I can also imagine ways in which these three models are used in combination.
These are OER Sustainability Models so the practice of open is embedded right into the model. Open is not an add-on but an integral function of the model.
Each model focuses on high value proposition, social good, and large numbers of users / collaborators / partners. These three variables act as the foundation on which open sustainability models are built.
All three models are based on collaboration not competition. Sustainability entails collaborating with each other over time to generate, maintain and steward something of mutual value.
These sustainability models focus on value not finances. OER generate a multidude of value including increased education access, inclusion, adaptability, and quality. Knowing the purpose and value OER are intended to produce ensures sustainability models are built around the unique educational value OER creates.
The operational processes associated with these OER sustainability models are new and different than existing practices. The financial part of any OER sustainability model should be derived after the model is designed, based on these new processes.
More to Come
There is a huge need for easy to understand and replicable OER sustainability models. I hope these three examples prove useful and stimulate the creation of others. I think there is lots more to come around how to do this well. I look forward to sharing these ideas in SPARC Europe’s upcoming Open Education Cafe on this issue.
I expect many of you have thoughts and ideas on this topic too so I've created a Sustainability Models discussion forum in OEGlobal's Connect space. Welcome discussion and suggestions there.
Thanks to OEGlobal, and in particular @cogdog for providing this forum for discussion.

AI From an Open Perspective
The burst of Artificial Intelligence (AI) onto the scene at the start of 2023 caught my interest along with everyone else. Over the course of my high tech career the sudden emergence of a new technology and the ensuing hype cycle has been a common occurrence. But AI was over the top - seemingly everywhere, affecting all endeavours, with a relentless hype cycle full of fears and hopes.
When a new technology like this takes off I like to get hands-on with it. So I began experimenting with Chat-GPT and DALL-E. I was impressed with the clear, concise, and well written answers ChatGPT generated. It seemed thoughtful, well spoken, almost human. It came across as definitive and seemingly authoritative. However, deeper queries about things I’m more expert in generated superficial or incomplete answers. Direct queries asking ChatGPT what sources it used to generate its responses were not answered and the so-called “hallucinations'“ it had generating fictitious references were disturbing.
As an artist I was amazed at DALL-E’s ability to create an image based on a text prompt, fascinating to observe how it can readily combine disparate objects, and fun to see how initial creations morph based on changes to initial text prompt or requesting a specific style like Impressionism. However, I didn’t really think the images generated were mine or represented my artistic expression and I wondered about legalities associated with use of the image.
Underlying Data Set
I began to wonder about the underlying data set used to generate AI responses. Where did that data come from and how reliable is it? In computer science, there is a saying “garbage in, garbage out”. If AI is based on flawed internet data then the responses it generates may be wrong, inaccurate, or biased. It seems to me the sources and quality of the underlying data set used to train the AI are of paramount importance. I spent some time digging in to this and came up with some answers which I provide below. But details about the data are undisclosed. This lack of transparency makes open AI less open and leads to speculation and uncertainty.
The research article “Language Models are Few-Shot Learners” provides a good summary of ChatGPT’s underlying data and articles like “ChatGPT — Show me the Data Sources”, “OpenAI GPT-3: Everything You Need to Know”, and “Inside the secret list of websites that make AI like ChatGPT sound smart” provide additional context and analysis. ChatGPT builds its data model from several different sources of data scraped from the web (CommonCrawl, WebText2, Books1, Books2, Wikipedia). The multiple sources of data are used to enhance quality. It is interesting to learn that during training, datasets are not sampled in proportion to their size. Datasets viewed as higher-quality are sampled more frequently. The CommonCrawl and Books2 datasets are sampled less than once during training but Wikipedia is sampled over 3 times indicating a higher quality value associated with Wikipedia. It is fascinating to learn that an openly licensed (CC BY-SA) source like Wikipedia is so important to AI.
“Wikipedia’s value in the age of generative AI” notes:
“The process of freely creating knowledge, of sharing it, and refining it over time, in public and with the help of hundreds of thousands of volunteers, has for 20 years fundamentally shaped Wikipedia and the many other Wikimedia projects. Wikipedia contains trustworthy, reliably sourced knowledge because it is created, debated, and curated by people. It’s also grounded in an open, noncommercial model, which means that Wikipedia is free to access and for sharing, and it always will be. And in an internet flooded with machine generated content, this means that Wikipedia becomes even more valuable.”
“In the past six months, the public has been introduced to dozens of LLMs, trained on vast data sets that can read, summarize, and generate text. Wikipedia is one of the largest open corpuses of information on the internet, with versions in over 300 languages. To date, every LLM is trained on Wikipedia content, and it is almost always the largest source of training data in their data sets.”
“Wikipedia’s Moment of Truth” has this to say:
“While estimates of its influence can vary, Wikipedia is probably the most important single source in the training of A.I. models.”
“Wikipedia going forward will forever be super valuable, because it’s one of the largest well-curated data sets out there. There is generally a link between the quality of data a model trains on and the accuracy and coherence of its responses.”
That said the use of open licensed resources for training AI is contentious.
The origins of the tension begin back in 2014 and are well documented by OpenFuture. As they note “by then there were almost 400 million CC-licensed photos on Flickr. That year researchers from Yahoo Labs, Lawrence Livermore National Laboratory, Snapchat and In-Q-Tel used a quarter of all these photos to create YFCC100M, a dataset of 100 million photographs of people created for computer vision applications. This dataset remains one of the most significant examples of openly licensed content reusing. Because of the massive scale and the productive nature of the dataset, it became one of the foundations for computer vision research and industry built on top of it. The YFCC100M dataset set a precedent, followed by many other datasets. Many of them became standardized tools used for training facial recognition AI technologies.” OpenFuture goes on to further note in their “AI Commons” report this case, "raised fundamental questions about the challenges that open licensing faces today, related to privacy, exploitation of the commons at massive scales of use, or dealing with unexpected and unintended uses of works that are openly licensed." These fundamental questions are driving a rethink of open.
Legal or Illegal
I’ve always wondered about scraping data from the web. Is that legal? There are contradicting views with judges in some cases saying it is legal in others illegal. However, assuming web scraping is legal (it certainly is a common practice) AI developers assert that their use of the content and data from web scraping such as the Common Crawl dataset that underlies ChatGPT, and LAION, the image data set used by DALL-E, are legal under fair use.
The Creative Commons article “Fair Use: Training Generative AI” provides a good overview of the considerations and lays out the case for fair use.
Fair use involves four factors:
The purpose and character of the use, including whether such use is of commercial nature or is for nonprofit educational purposes
Courts typically focus on whether the use is “transformative.” That is, whether it adds new expression or meaning to the original, or whether it merely copies from the original.
The nature of the copyrighted work
Using material from primarily factual works is more likely to be fair than using purely fictional works.
The amount and substantiality of the portion used in relation to the copyrighted work as a whole
Borrowing small bits of material from an original work is more likely to be considered fair use than borrowing large portions. However, even a small taking may weigh against fair use in some situations if it constitutes the “heart” of the work.
The effect of the use upon the potential market for, or value of, the copyrighted work
I think the fair use argument is pretty sound when it comes to transformative purpose and use, primarily factual use, and amount and substantiality. But the fourth factor, impact on market, is more contentious.
In addition to Common Crawl and Wikipedia, ChatGPT uses the WebText2, Books1, and Books2 data sets. The article “AI Training Datasets: the Books1+Books2 that Big AI eats for breakfast” contains a good summary of those data sets. Of particular interest is just how opaque these data sets are. In the context of “open” it’s fair to say these data sets are not very open. Also of great interest to me were the identified two flaws to the data sets:
no knowledge of current events whatsoever. An AI formed by static datasets is effectively a “knowledge time capsule” that gets stale with age.
no sensory data to give it practical knowledge of the real world. An analogy might be a human in a coma, whose only functioning organs are its eyes and its brain, and who has the text of every book, magazine and newspaper ever printed sequentially scrolled in front of its eyes, with no way to view anything else, ever. No pictures, no movies, no fingers, no touch, no sound, no music, no taste, no talking, no smell, no walking or talking or eating or…. Just… 100% reading. And that’s it.
Despite the assertion that these data sets are provided under fair use, it is contentious. There are lots of ongoing debates and lawsuits. For example “Authors Accuse OpenAI of Using Pirate Sites to Train ChatGPT” and “Authors file lawsuit against OpenAI alleging using pirated content for training ChatGPT” describe a class action lawsuit against OpenAI, accusing ChatGPT’s parent company of copyright infringement and violating the Digital Millennium Copyright Act (DMCA). According to the authors, ChatGPT was partly trained on their copyrighted works, without permission. The authors never gave OpenAI permission to use their works, yet ChatGPT can provide accurate summaries of their writings something only possible if ChatGPT was trained on Plaintiffs’ copyrighted works. It also suggests these books were accessed through pirate websites something it appears other AI developers may also be doing.
It is fair use factor four “the effect of the use upon the potential market’ that is perhaps most hotly contested.
“Artists Are Suing Artificial Intelligence Companies and the Lawsuit Could Upend Legal Precedents Around Art” is a good summary of some of the issues associated with image generating AI.
“Record label battles with generative AI carry lessons for news industry” reflects some of the battles related to music.
Loss of income, jobs and livelihood seem highly pertinent to “effect of the use upon the potential market”.
RAIL Licenses
In November of 2022 I had the good fortune to attend an AI Commons Roundtable at the Internet Archive in San Francisco hosted by Open Future. One thing really stands out for me from that round table. Historically “open”, in the context of education and culture, has relied on use of Creative Commons licenses which are based on copyright law. All of the AI legally contested cases referenced above present their legal arguments using intellectual property (IP) and copyright law. But at the roundtable we discussed whether IP and copyright are really the best legal means for managing AI. Are Creative Commons licenses relevant in the context of AI? Will Creative Commons licenses evolve in response to the fundamental questions and challenges open faces today?
I was fascinated to learn about the RAIL initiative and their licenses. Responsible AI Licenses (RAIL) empower developers to restrict the use of their AI technology in order to prevent irresponsible and harmful applications. These licenses include behavioural-use clauses which grant permissions for specific use-cases and/or restrict certain use-cases.
The basic premise is that open is not synonymous with good. Open may lower the barriers to harmful uses. In order to mitigate harm, including safety and security concerns, open licenses need to evolve from simply being “open” to being “open” and “ responsible”.
Here is an example of a Responsible AI End User License Agreement. Of particular interest is the part 4 of the license describing “Conduct and Prohibitions”. The list of prohibitions is extensive and addresses many of the concerns that have been raised about AI. I recommend you read the entire list but here is a small sampling of the kinds of prohibitions specified.
The introductory Conduct and Prohibitions section includes agreeing not to:
“stalk,” harass, threaten, or invade privacy
impersonate any person or entity
collect, store, or use personal data
along with lots of other requirements
Under Surveillance, among other things, it prohibits use of AI to:
Detect or infer aspects and/or features of an identity any person, such as name, family name, address, gender, sexual orientation, race, religion, age, location (at any geographical level), skin color, society or political affiliations, employment status and/or employment history, and health and medical conditions.
A Computer Generated Mediated prohibition is agreement not to:
Synthesize and/or modify audio-realistic and/or video-realistic representations (indistinguishable from photo/video recordings) of people and events, without including a caption, watermark, and/or metadata file
Some Health Care prohibitions are to not to use AI to:
Predict the likelihood that any person will request to file an insurance claim or
Diagnose a medical condition without human oversight
A Criminal prohibition includes agreeing not to:
Predict the likelihood, of any person, being a criminal, based on the person’s facial attributes or another person’s facial attributes
These are but a sample, the full text of RAIL licenses covers even more territory when it comes to ethical and responsible use. It is interesting to reflect on whether the requirements and prohibitions specified in RAIL licenses are comprehensive enough to curb all ethical concerns. Personally, I think it would be helpful to specify not just what you can’t do in the form of“prohibitions” but what you encouraged to do in the form of “permissions”.
See “The Growth Of Responsible AI Licensing” for a summary on adoption and use of RAIL licenses.
Behavioural-use clauses are based more on contract law than copyright.
When I worked at Creative Commons (CC) I advocated for an addition to all Creative Commons licenses that would enable creators to express their intent. My belief was that expression of intent and downstream fulfillment of that intent would lead to more and better sharing. While expression of intent never came to be included in CC licenses I am finding it fascinating that intent is a significant aspect of AI. There are two aspects to intent in AI. Intent of the creators of AI as expressed in the licenses under which they make their tools available (eg. RAIL Licenses) and the ability of AI to understand user intent. See “User Intent: How AI Search Delivers What Users Want” for a bit more on user intent. I think the recognition of intent as being an essential aspect of AI is an tremendously important. And I applaud the development of behaviour-use clauses in licenses that aim to limit exploitation.
In the context of open education I published a similar set of behaviour recommendations in “Commons Strategy for Successful and Sustainable Open Education”. My aim was to go beyond mere legal compliance to define a set of behaviours associated with being a good actor in open education. I defined detrimental behaviour and constructive behaviours. Example constructive were situated along a continuum going from Positive First Step to Optimal. Providing behavioural guidance makes it clear that open entails going beyond mere legal compliance to responsibly stewarding an open commons using norms and practices.
In “On the emerging landscape of open AI”Alek Tarkowski notes, “Open vs responsible” is now a big topic in AI circles. But it also raises questions for the broader space of open sharing and for companies and organizations built on open frameworks. And it signals an urgent need to revisit open licensing frameworks. Anna Mazgal calls this “a singularity point for open licensing” and also argues for a review of open licenses from a fundamental rights perspective.” I’ll be attending the upcoming Creative Commons Global Summit in Mexico city and look forward to participating, with others from around the world, in reimagining open licensing frameworks.
Making Layers of AI Open
When considering AI from an open perspective the underlying data set is just one consideration. I’ve been looking at diagrams of the AI technology stack with the aim of getting a handle on what the layers of AI architecture are and which layers are, or could be, open.
This generative AI tech stack diagram by a16z provides a good starting point:

At the bottom is a layer of special high performance compute hardware with accelerator chips optimized for AI model training and inference. This layer is high cost such that only big high tech players can afford to build it out.
Above that are Cloud Platforms making the compute hardware available to AI developers in a cloud deployment model. Cloud platforms provide tools and interfaces for data scientists, IT professionals and, non-technical business staff to create AI-based applications. Providing access to Compute Hardware through the cloud makes AI development less costly and more feasible for smaller enterprises.
The middle layer is comprised of models close sourced but exposed via API’s to developers and models open sourced, hosted on model hubs like Hugging Face and Replicate.
The models are used to create end user facing applications with and without proprietary models.
I like this generative AI stack diagram but it is missing an important element I’ve already discussed - Data. AI models derive their value from the data they’re trained on. So, there’s a need to factor in data.
Here’s an AI diagram from the AI Infrastructure Alliance showing data and model training in more detail:

It is interesting to see the data is not used in raw form but goes through a series of processes to enhance the quality of the data - clean, validate, transform, label. These steps involve humans who must sift through the data to identify and prevent objectionable materials appearing in output. From an open perspective I wonder whether this cleaned data is considered proprietary to the AI developer? If Wikipedia data is “cleaned” or “ transformed” surely there is a requirement to share that back via the open license Wikipedia uses - CC BY-SA? Perhaps all cleaned data, scraped from the web, should be openly licensed so others don’t have to go through the same cleaning process?
Models
I like the way the diagram shows the AI Machine Learning workflow associated with training a model based on source data. Machine learning (ML) is an AI technique that uses mathematical algorithms to create predictive models. An algorithm is used to parse data fields and to "learn" from that data by using patterns found within it to generate models. Those models are then used to make informed predictions or decisions about new data with considerable accuracy. The predictive models are validated against known data, measured by performance metrics selected for specific use cases, and then adjusted as needed. This process of learning and validation is called training and produces a trained model or models.
This diagram from LeewayHertz modifies the generative AI stack diagram presented earlier to show different types of trained AI models.

General AI models aim to replicate human-like thinking and decision-making processes. They are intended to be versatile and adaptable, able to perform a wide range of tasks and learn from experience.
Foundation models are a recent development, in which AI models are developed from algorithms designed to optimize for generality and versatility of output. Those models are often trained on a broad range of data sources and large amounts of data to accomplish a wide range of downstream tasks, including some for which they were not specifically developed and trained. Those systems can be unimodal or multimodal, trained through various methods such as supervised learning or reinforced learning. AI systems with specific intended purpose or general purpose AI systems can be an implementation of a foundation model, which means that each foundation model can be reused in countless downstream AI or general purpose AI systems. These models hold growing importance to many downstream applications and systems.” Foundation Models can handle a broad range of outputs across categories such as text, images, videos, speech, code and games.
These General and Foundation models are designed to be user-friendly and open-source, representing a starting point for specific AI applications. The open source character of these models is important. It takes a lot of effort to create a general or foundation model. Making that available to others who can then add a small amount of custom data to the general or foundation model enables widespread use.
The sophistication and performance of a general AI model is judged by how many parameters it has. A model’s parameters are the number of factors it considers when generating output. The main difference between ChatGPT-2 and ChatGPT-3 is the size of the model. ChatGPT-2 is a smaller model with 1.5 billion parameters, while ChatGPT-3 is much larger with 175 billion parameters. This means that ChatGPT-3 is able to process more data and learn more complex relationships between words. It is interesting to learn that the conventional view of AI models being as smart as they are because of the vast amount of data on the internet today is false. It turns out that a smaller amount of high quality data with a larger model (expressed in parameters), is a better way to go.
However, general or foundation models aren’t naturally suited to all applications. For tasks requiring fully referenced high levels of accuracy specific models may be better.
I learned more about foundation models from IBM’s '“What are Foundation Models?” and Red Hats “Building a Foundation for AI Models”.
As noted in the Red Hat video foundation models aren’t usually deployed in an AI application. Instead they go through further training using specific data resulting in the creation of a Specific AI model, also known as domain-specific model, designed to excel in specific tasks. These models are trained on highly specific and relevant data, allowing them to perform with greater nuance and precision than general or foundation AI models. Most specific AI models are currently proprietary but as AI continues to evolve, specialized models are expected to become more open-sourced and available to a broader range of users.
Hyperlocal AI models go even further building even more capability from detailed data. They can achieve high levels of accuracy and specificity in their outputs generating outputs with exceptional precision. HyperLocal models are designed to be specialists in their fields, enabling them to produce highly customized and accurate outputs aligned to specific needs.
AI models are key elements of the AI world. From an open perspective a “model” is separate and distinct from the underlying source data, and and above layers of source code that make up the AI application. The model itself is licenseable.
The Turing Way Machine Learning Model Licenses provides a good overview of the licenses used for training models including the use of RAIL licenses. As they note, “While many ML models may utilise open software licensing (for example MIT, Apache 2.0), there are a number of ML model-specific licenses that may be developed for a specific model (for example OPT-175B license, BigScience BLOOM RAIL v1.0 License), company (for example Microsoft Data Use Agreement for Open AI Model Development), or series of models (for example BigScience OpenRAIL-M (Responsible AI License)).
From an open perspective it is interesting to see this growing list of ML licenses. It is particularly fascinating to see these new licenses go beyond the terms of prior open licenses generating new licensing options. However, it does raise a question around proliferation of licenses, their compatibility, and the extent to which they hinder or enable AI.
Complicating the picture are the big AI players who are creating their own special licenses. “Meta launches Llama 2, a source-available AI model that allows commercial applications" describes Meta’s approach and some of their considerations:
“Meta launched Llama 2, a source-available AI model that allows commercial applications" notes the recent Meta announcement of Llama 2, a new source-available family of AI language models notable for its commercial license, which means the models can be integrated into commercial products, unlike its predecessor.
In February, Meta released the precursor of Llama 2, LLaMA, as source-available with a non-commercial license. Officially only available to academics with certain credentials, someone soon leaked LLaMA's weights (files containing the parameter values of the trained neural networks) to torrent sites, and they spread widely in the AI community. Soon, fine-tuned variations of LLaMA, such as Alpaca, sprang up, providing the seed of a fast-growing underground LLM development scene.
Llama 2 brings this activity more fully out into the open with its allowance for commercial use, although potential licensees with "greater than 700 million monthly active users in the preceding calendar month" must request special permission from Meta to use it, potentially precluding its free use by giants the size of Amazon or Google.
While open AI models with weights available have proven popular with hobbyists and people seeking uncensored chatbots, they have also proven controversial. Meta is notable for standing alone among the tech giants in supporting major openly-licensed and weights-available foundation models, while those in the closed-source corner include OpenAI, Microsoft, and Google.
Critics say that open source AI models carry potential risks, such as misuse in synthetic biology or in generating spam or disinformation. It's easy to imagine Llama 2 filling some of these roles, although such uses violate Meta's terms of service. Currently, if someone performs restricted acts with OpenAI's ChatGPT API, access can be revoked. But with the open approach, once the weights are released, there is no taking them back.
However, proponents of an open approach to AI often argue that openly-available AI models encourage transparency (in terms of the training data used to make them), foster economic competition (not limiting the technology to giant companies), encourage free speech (no censorship), and democratize access to AI (without paywall restrictions).
Perhaps getting ahead of potential criticism for its release, Meta also published a short "Statement of Support for Meta's Open Approach to Today's AI" that reads, "We support an open innovation approach to AI. Responsible and open innovation gives us all a stake in the AI development process, bringing visibility, scrutiny and trust to these technologies. Opening today’s Llama models will let everyone benefit from this technology."
The proliferation of licenses and the desire to have them address responsible and ethical issues suggests a need for different licensing bodies to dialogue and coordinate definitions and uses of open licenses across all layers of the AI tech stack.
“Generative AI and large language models: background and contexts” provides a thorough review of large language models including open source ones and the range of issues around them. Of additional interest are the descriptions of specialist models and the potential for content generators/owners such as publishers to become the unexpected winners as LLMs become more widely used.
“The value of dense, verified information resources increases as they provide training and validation resources for LLMs in contrast to the vast uncurated heterogeneous training data scraped from the web. The potential of scientific publishers, Nature and others, whose content is currently mostly paywalled and isolated from training sets is highlighted along with the largest current domain-specific model BloombergGPT created from a combination of Bloomberg's deep historical reservoir of financial data ad more general publicly available resources.”
It goes on to say:
“The position of Hugging Face is very interesting. It has emerged as a central player in terms of providing a platform for open models, transformers and other components. At the same time it has innovated around the use of models, itself and with partners, and has supported important work on awareness, policy and governance.
It will also be interesting to see how strong the non-commercial presence is. There are many research-oriented specialist models. Will a community of research or public interest form around particular providers or infrastructure?”
The AI Infrastructure Alliance has an AI Infrastructure Landscape map showing machine learning operations and training activities along with which platforms handle various workflows and workloads including those who are open sourced.
As noted with the specific and hyperlocal model descriptions one of the central developments in AI is iterating models where pre-trained models are trained or fine-tuned a little bit more on a much smaller dataset. This AI is Eating the World diagram shows three ways for iterating a model:

The user data in this diagram is of particular interest as can be seen in this diagram where we see customization of models occurring through two methods, one involving ingestion of proprietary data and the other involving customizatin through use of user data including prompts and AI generations:

From an open perspective there are several key factors to consider with this representation of iterating models.
First Users own their own data. Use of that data by the AI developer must be based on users having openly licensed that data or allowing the developer to use their data based on Terms of Use typically agreed to as a precondition of using the AI application.
Zoom’s attempt to redefine their Terms of Service to authorize use of user data to improve their AI shows repercussions of trying to force this on users. See “Zoom's Updated Terms of Service Permit Training AI on User Content Without Opt-Out”
A second factor is related to a fascinating aspect of AI generation - Who owns AI generated output?
As Paul Keller notes in “AI, The Commons, And The Limits Of Copyright” "we need to move away from the analytical framework provided by copyright, which is based on the ownership of individual works, and recognize that what generative ML models use are not individual works for their individual properties but rather collections of works of unimaginable size: state-of-the-art image generators are trained on billions of individual works, and text generators are regularly trained on more than 100 billion tokens." It’s crucially important to understand that there is a fundamental difference between reproducing content and generating content. Generative AI doesn’t reproduce content from source data it generates new content.
The US Copyright Office provides general guidance on the copyrightability of generative AI outputs through the Compendium of U.S. Copyright Office Practices. The Compendium’s language rejects as uncopyrightable all works produced by a machine or mere mechanical process that operates randomly or automatically without any creative input or intervention from a human author. As noted in “Who Ultimately Owns Content Generated By ChatGPT And Other AI Platforms?” “For a work to enjoy copyright protection under current U.S. law, the work must be the result of original and creative authorship by a human author. Absent human creative input, a work is not entitled to copyright protection. As a result, the U.S. Copyright Office will not register a work that was created by an autonomous artificial intelligence tool.” The article “AI-generated art can be copyrighted, say US officials – with a catch” provides additional nuance to this position. If AI outputs are not subject to copyright then it begs the question, “Are AI outputs in the public domain?”
There are increasing discussions about whether prompts should themselves be openly licensed. Underlying that is what permissions users of AI technologies like ChatGPT are giving the company (OpenAI) who owns that technology. We’ve already discussed OpenAI use of data or content you may have produced in their underlying data set. However, what about your questions, prompts and other interactions associated with use of ChatGPT as shown in the model iteration diagram above. Can OpenAI use your inputs to improve their model? “How your data is used to improve model performance” makes it clear that “ChatGPT, improves by further training on the conversations people have with it, unless you choose to disable training.” Kudos to OpenAI for providing an option to opt out, “you can switch off training in ChatGPT settings (under Data Controls) to turn off training for any conversations created while training is disabled or you can submit this form. Once you opt out, new conversations will not be used to train our models.” The default mining of end user data is a continuation of large platform tactics. You are knowingly or unknowingly contributing to AI through data scraped from the web and through your interactions with AI tools. From an open perspective this default setting ought to be that end user data ownership and privacy requires opt in, not opt out, agreement around use of data in model iteration and improvement efforts.
I find it particularly interesting to see the increasing focus on prompts used in AI systems rather than the content generated. David Wiley writes a couple of interesting blog posts (see here and here) exploring “what if, in the future, educators didn’t write textbooks at all? What if, instead, we only wrote structured collections of highly crafted prompts? Instead of reading a static textbook in a linear fashion, the learner would use the prompts to interact with a large language model.” David goes on to note that “yes, you could openly license your generative textbook (collection of prompts). But the fundamental role of OER changes dramatically in future scenarios where the majority of the learning material a student engages with is generated on the fly by an LLM, and was never eligible for copyright protection in the first place.”
Applications
Many AI platforms make their foundation and other models available to other developers via API’s. This enables others to build unique applications on top of foundation models or customize a foundation model with their own data to perform a specific task.
End user applications at the top of the AI tech stack automate and deliver a variety of task-based capabilities ranging from image generation, to general writing, tutoring / advising, and code generation.
There are a wide range of diagrams showing the AI application landscape. The landscape is rapidly changing but here is a simple diagram from Sequoia showing model and application layers across multiple fields.
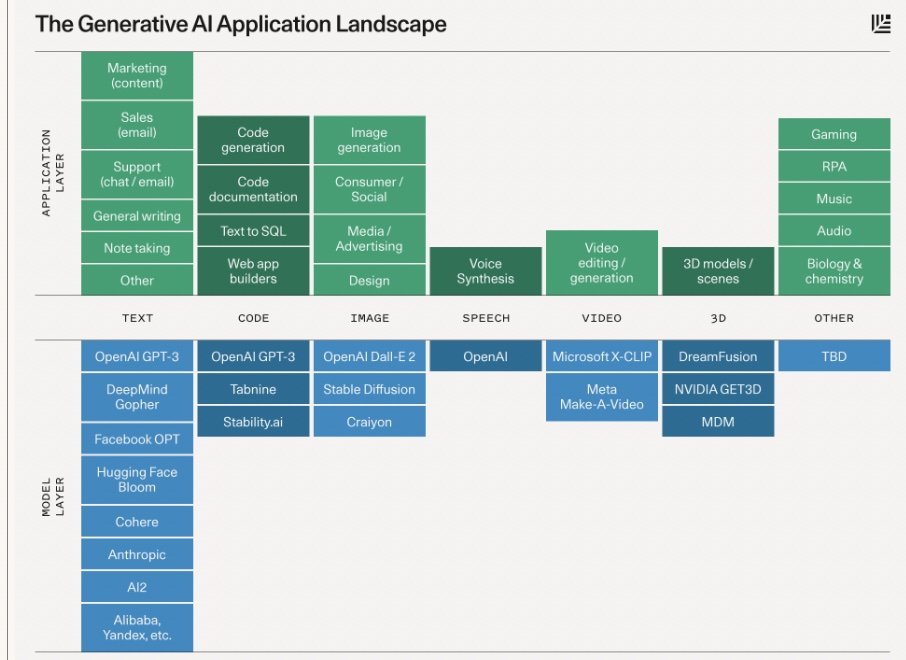
From an open perspective the apps and applications that perform these tasks are open licenseable. The blog post "From Rail To Open Rail: Topologies of Rail Licenses" explores real-world questions around (i) the nature of artifacts being licensed - i.e. the data, source, model, binaries/executables, (ii) what could constitute derivative works for each, (iii) whether the artifact’s license enables permissive downstream distribution of such artifact and any derivative versions of it (e.g. with commercial terms of any kind). This provides essential background to the use of RAIL licenses. Example RAIL licenses are provided for AI models (AIPubs OpenRAIL-M), AI source code (AIPubs OpenRAIL-S), and responsible AI end user licenses (RAIL-A License).
OpenAI's "Introducing ChatGPT and Whisper APIs" blog post describes how they open license code and models and “Whispers of A.I.’s Modular Future” chronicles one persons use of Whisper a model capable of transcribing speech in more than ninety languages.
This diagram from Deedy maps applications in the AI language sector against the AI stack. Deedy’s diagram places the stack horizontally along the x axis rather than vertically as in previous diagrams. Doing so gives a kind of sense of progression and the complex inter-relationships across layers of the stack.

Application Programming Interfaces (APIs)
This diagram also shows a new layer to the tech stack called “Framework / API”. AI developers are hosting models and development tools in the cloud and making it possible for others to use these models and development tools via API’s.
An API, or application programming interface, is a system that allows two or more two or more software programs to interact and understand each other without communication problems. You could think of it as a sort of intermediary that helps one software program share information with another one. An open API is based on an open standard, which specifies the mechanism which queries the API and interprets its responses. A closed API refers to technology that can only be used by the developer or the company that created it. An open API is different in that any developer has free access to it via the Internet. This allows organizations to integrate AI into the software tools they use every day gaining access to certain features of a software program that would be difficult to access without taking the time to develop a large amount of code.
Companies, like OpenAI, develop their own apps and make them available via an API so that other companies can also use them. This type of arrangement offers a win-win situation for both companies. The developing company generates revenue from other companies that use their app, and the company using the app gets greater efficiency or functionality.
The “Gradient of Generative AI Release: Methods and Considerations” does a great job of describing six levels of access to generative AI system models: fully closed; gradual or staged access; hosted access; cloud-based or API access; downloadable access; and fully open. Each level, from fully closed to fully open, can be viewed as an option along a gradient.
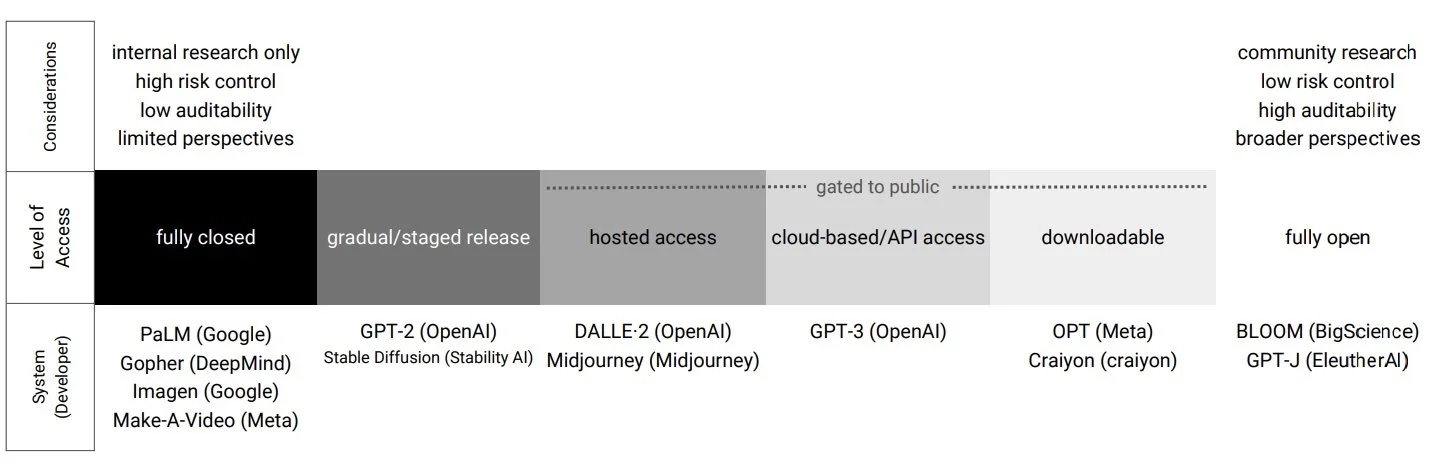
The paper outlines key considerations across this gradient taking note of the tradeoffs, especially around the tension between concentrating power and safety. It also shows trends in generative system release over time, noting closedness among large companies for powerful systems and openness among smaller organizations founded with the intent to be open. It is unclear at this time whether movements towards openness will pressure historically closed organizations to adjust their release strategies.
It’s been super helpful for me to see these different representations of the AI tech stack as a means to understanding the layers that make up AI and the extent to which they are open. It is clear that Open source in AI is very well established. As "The AI renaissance and why Open Source matters" says:
“Sharing knowledge and sharing code has always been a key driver for innovation in Artificial Intelligence. Researchers have gathered together since AI was established as a field to develop and advance novel techniques, from Natural Language Processing to Artificial Neural Networks, from Machine Learning to Deep Learning. The Open Source community has played a key role in advancing AI and bringing it to solve real-world problems. …”
However, "The AI renaissance and why Open Source matters" goes on to say:
"The world of AI is at an important crossroads. There are two paths forward: one where highly regulated proprietary code, models, and datasets are going to prevail, or one where Open Source dominates. One path will lead to a stronghold of AI by a few large corporations where end-users will have limited privacy and control, while the other will democratize AI, allowing anyone to study, adapt, contribute back, innovate, as well as build businesses on top of these foundations with full control and respect for privacy."
Open Across the AI Tech Stack Layers
While open is already integral to AI, nowhere did I find a diagram representing all the ways open is playing out across the different layers in the AI tech stack. In the absence of such a diagram I created my own, expanding the stack to show the API layer along with user interactions and generative AI output. An open perspective of open licensing considerations and questions is provided to the right of each stack layer.

Learning
I’m interested in AI in the context of open writ large. But a great deal of my career has focused on open in the context of education. I’m super impressed with the effort in academia to identify ways to use AI such as:
and many more including the role of open practices:
But what about the pedagogical ways in which AI is being trained. What are the pedagogies being used to develop artificial intelligence? To what extent is AI using contemporary learning theories and pedagogical approaches? Is AI automating poor pedagogical practices? When compared with human teachers and contemporary pedagogy is AI better?
Machine learning (ML), Deep learning, Large Language Learning Models (LLM), and other such terms pervade the AI literature. The “Difference Between Artificial Intelligence vs Machine Learning vs Deep Learning” provides a good overview. AI learning heavily relies on math, engineering and behaviourist models of learning. This underlying approach to learning lacks much of what we know in terms of contemporary pedagogy and limits the usefulness of AI in terms of engaging learners intellectually, physically, culturally, emotionally and socially. Compared to human teachers AI is, currently, very limited.
From the perspective of open the field of open education has much to offer including:
Open Educational Resources
Open Pedagogies
Open Access
Open Science and
Open Data
It will be interesting to see whether AI advances in terms of using more contemporary pedagogies in the underlying learning process used to train AI and in the ways it engages those using it.
Ethics
Part of what makes AI interesting, and contentious, are questions that are less legal and more ethical. Here is a sample of the many ethical concerns being expressed:
Is AI the greatest art heist in history?
"AI art generators are trained on enormous datasets, containing millions upon millions of copyrighted images, harvested without their creator’s knowledge, let alone compensation or consent. This is effectively the greatest art heist in history. Perpetrated by respectable-seeming corporate entities backed by Silicon Valley venture capital. It’s daylight robbery." Restrict AI Illustration from Publishing: An Open Letter
Is AI the appropriation of the “sum total of human knowledge”?
“Are we "witnessing the wealthiest companies in history (Microsoft, Apple, Google, Meta, Amazon …) unilaterally seizing the sum total of human knowledge that exists in digital, scrapeable form and walling it off inside proprietary products, many of which will take direct aim at the humans whose lifetime of labor trained the machines without giving permission or consent." AI machines aren’t ‘hallucinating’. But their makers are, Naomi Klein
Can AI solve the United Nations’ Sustainable Development Goals (SDGs)?
"We have less than 10 years to solve the United Nations’ Sustainable Development Goals (SDGs). AI holds great promise by capitalizing on the unprecedented quantities of data now being generated on sentiment behaviour, human health, commerce, communications, migration and more. The goal of AI for Good is to identify practical applications of AI to advance the United Nations Sustainable Development Goals and scale those solutions for global impact. It’s the leading action-oriented, global & inclusive United Nations platform on AI. AI for Good is organized by ITU in partnership with 40 UN Sister Agencies and co-convened with Switzerland." AI For Good
Will AI be marshalled to benefit humanity, other species and our shared home?, or Is AI built to maximize the extraction of wealth and profit?
“Will AI be "marshalled to benefit humanity, other species and our shared home?", or Is AI "built to maximize the extraction of wealth and profit – from both humans and the natural world" making it "more likely to become a fearsome tool of further dispossession and despoilation." AI machines aren’t ‘hallucinating’. But their makers are.” AI machines aren’t ‘hallucinating’. But their makers are, Naomi Klein
Will AI reproduce real world biases and discrimination fueling divisions and threatening fundamental human rights and freedoms?
"AI technology brings major benefits in many areas, but without the ethical guardrails, it risks reproducing real world biases and discrimination, fueling divisions and threatening fundamental human rights and freedoms." Message from Gabriela Ramos Assistant Director-General, Social and Human Sciences, UNESCO in Recommendation on the Ethics of Artificial Intelligence
Will AI develop rapidly and exponentially such that it surpasses human intelligence?
“The technological singularity is a hypothetical future event in which technological progress becomes so rapid and exponential that it surpasses human intelligence, resulting in a future in which machines can create and improve upon their own designs faster than humans can. This could lead to a point where machines are able to design and build even more advanced machines, leading to a runaway effect of ever-increasing intelligence and eventually resulting in a future in which humans are unable to understand or control the technology they have created. Some proponents of the singularity argue that it is inevitable, while others believe that it can be prevented through careful regulation of AI development.” AI For Anyone - Technological Singularity
Should private corporations be allowed to run uncontrolled AI experiments on the entire population without any guardrails or safety nets?
“The question we should be asking about artificial intelligence – and every other new technology – is whether private corporations be allowed to run uncontrolled experiments on the entire population without any guardrails or safety nets. Should it be legal for corporations to release products to the masses before demonstrating that those products are safe?” There Is Only One Question That Matters with AI
To these I might add:
Is it fair that the citizens who have generated the data necessary to train models have no input on how their data is used?
What are the repercussions of AI use leading to misinformed or unjustified actions?
Will AI propagate harmful and historically dominant perspectives?
Will AI further concentrate economic or cultural power?
Will AI have a social impact on employment, work quality and exploited labor?
What is the potential overall effect of AI on society?
As “AI Creating 'Art' Is An Ethical And Copyright Nightmare” notes AI “has been fun for casual users and interesting for tech enthusiasts, sure, but it has also created an ethical and copyright black hole, where everyone from artists to lawyers to engineers has very strong opinions on what this all means, for their jobs and for the nature of art itself.”
In “Common Ethical Challenges in AI” the Council of Europe shares a map of the concerns from their perspective:
The article "Legal and Ethical Consideration in Artificial Intelligence in Healthcare: Who Takes Responsibility?" identifies four major ethical issues: (1) informed consent to use data, (2) safety and transparency, (3) algorithmic fairness and biases, and (4) data privacy.
UNESCO has published a “Recommendation on the Ethics of Artificial Intelligence” and recently announced a partnership between UNESCO and the EU to speed up the implementation of ethical rules.
Another UNESCO initiative, specific to education, generated the publication "AI and education: Guidance for policy-makers". I really like this as a great overview for policy makers on how AI affects education including promising examples, challenges associated with use, and approaches to policy. I admire the work Wayne Holmes is doing in this field and look forward to the outputs of his work with the Council of Europe developing regulation dealing with the application and use of AI systems within educational contexts.
There seems to be a consensus, even among AI developers, that thoughtful rules and guardrails are required to maximize AI’s potential for good and minimize the potential harms. However, at this point it seems that the way these responsible and ethical questions are going to be answered is through court cases and regulation.
Given the importance of open across all aspects of AI, I think the open movement should be more involved and proactive in advocating for openness too and shaping what regulation should look like.
AI Regulation
In some ways the emergence and evolution of AI seems to be following the same pattern as previous digital platforms. "AI makes rules for the metaverse even more important" describes it this way:
“In Act One, visionary innovators imagine what wonders digital technology can deliver and then bring them to life. The hype and hustle surrounding the metaverse recycles the “move fast and break things” mantra of the early internet. The focus last time was on what can be built rather than consideration of its consequences—should we expect anything different this time?
Act Two was the refinement of the technology’s application. By marrying computer science with behavioral science, such as casino psychology research, the platform companies were able to design applications to maximize their monetary potential. Today’s reprise moves beyond psychological science to embrace neurological science. One commentator has called out the “Three M’s of the Metaverse” —monitor users, manipulate users, and monetize users.
The unfinished Act Three features governments trying to keep pace with the tech companies racing ahead to establish their own behavioral rules. In the U.S., policymakers have stumbled around trying to determine what actions (if any) to take. Across the Atlantic, the European Union and the United Kingdom have moved forward to establish new rules for the internet we know today.
The challenge society now faces is determining whether there will be a stage manager for the new activities; not a director that dictates, but a supervisor that coordinates what is needed for the performance and its effect on the audience. Will the metaverse companies put their own stage management in place for the metaverse just like they did for their internet platforms? Or will the governments that were slow on the uptake in the early generation internet see the vast new developments of the metaverse as the trigger to assert themselves?”
AI needs a different approach. AI regulations, rules and norms ought to encourage use of open as a means of establishing ethical and responsible values, ensuring transparency, creating public good, stimulating AI innovation, mitigating risk, and generating new business models.
In "Advocating for Open Models in AI Oversight: Stability AI's Letter to the United States Senate" CEO Emad Mostaque says:
“These technologies will be the backbone of our digital economy, and it is essential that the public can scrutinize their development. Open models and open datasets will help to improve safety through transparency, foster competition, and ensure the United States retains strategic leadership in critical AI capabilities. Grassroots innovation is America’s greatest asset, and open models will help to put these tools in the hands of workers and firms across the economy.”
Machine Learning Street Talk has some great resources on AI including video clips and analysis of testimony at the US Senate hearings on AI oversight. In this clip Sam Altman, CEO of OpenAI, says :
“I think it’s important that any new approach, any new law, does not stop the innovation from happening with smaller companies, open source, researchers that are doing work at a smaller scale. Thats a wonderful part of this ecosystem, … and we don’t want to slow that down.”
Open source is already part of the AI ecosystem and is integral to many of the ethical and safety aims. However I’ve yet to see anything that proactively and clearly articulates the role of open across the AI stack and opens role in AI regulation, rules and norms.
The use of artificial intelligence in the EU will be regulated by the AI Act, the world’s first comprehensive AI law, at the time of this writing still in draft. This Regulation lays down a uniform legal framework for the development, the placing on the market and putting into service, and the use of artificial intelligence. Here is a good short summary of the intent of this regulation along with accompanying remarks from an open perspective.
“The parliamentary priority is to make sure AI systems are safe, transparent, traceable, non-discriminatory and environmentally friendly. “
Openness is a key means of ensuring AI Act priorities are met, especially as it relates to transparency, traceability and non-discrimination. The practice of open makes resources, whether they be source code or other digital media, freely open to others to view, use, modify and redistribute. It does so in ways that do not discriminate against any individual or group of people, meaning they must be truly accessible by anyone.
“The EU AI Act has different rules for different risk levels including:
1. Unacceptable Risk AI systems that are considered a threat to people will be banned.
This includes AI systems such as:
Cognitive behavioural manipulation of people or specific vulnerable groups: for example voice-activated toys that encourage dangerous behaviour in children
Social scoring: classifying people based on behaviour, socio-economic status or personal characteristics
Real-time and remote biometric identification systems, such as facial recognition
2. All High Risk AI systems that negatively affect safety or fundamental rights will be assessed before being put on the market and also throughout their lifecycle.
High risk AI systems will be divided into two categories:
1) AI systems that are used in products falling under the EU’s product safety legislation. This includes toys, aviation, cars, medical devices and lifts.
2) AI systems falling into eight specific areas that will have to be registered in an EU database:
Biometric identification and categorisation of natural persons
Management and operation of critical infrastructure
Education and vocational training
Employment, worker management and access to self-employment
Access to and enjoyment of essential private services and public services and benefits
Law enforcement
Migration, asylum and border control management
Assistance in legal interpretation and application of the law.”
I anticipate adoption of these risk categories will have a somewhat chilling affect on AI. There will be a lot of attention paid to the definition of each risk category and what is included in each. The high risk category is very broad and the requirements extensive, including registration, stringent reviews, and quality / risk management. The fines for non-compliance are large.
My field is education so it is interesting to see education and training designated High Risk. AI is already in use in the education sector for a wide range of purposes, some of which, such as plagiarism detection and academic online testing surveillance are highly controversial. The AI Act suggests these will be banned or at the very least deemed high risk.
“Generative AI, like ChatGPT, would have to comply with transparency requirements such as:
Disclosing that the content was generated by AI
Designing the model to prevent it from generating illegal content
Publishing summaries of copyrighted data used for training”
Here again is a regulation statement calling for openness and transparency. It might be helpful to offer guidance on what open tools and licenses fullfill these requirements.
“3. Limited risk AI systems will have to comply with minimal transparency requirements that would allow users to make informed decisions. After interacting with the applications, the user can then decide whether they want to continue using it. Users should be made aware when they are interacting with AI. This includes AI systems that generate or manipulate image, audio or video content, for example deepfakes.”
Recent amendments to the AI act, as documented in this Draft Compromise Amendments, take an even more restrictive approach by extending regulations to AI foundation models. All foundation models are categorized as High Risk. It is not clear why foundation models are high risk but specific or hyperlocal models are not. The repercussions of this may result in AI development being focused more on highly tailored or specific models rather than foundation ones.
The Draft Compromise Amendments acknowledge the important role open source is already playing in the AI landscape and seeks to incentivize further open source efforts noting the following exemptions:
“(12a) Software and data that are openly shared and where users can freely access, use, modify and redistribute them or modified versions thereof, can contribute to research and innovation in the market. Research by the European Commission also shows that free and open-source software can contribute between €65 billion to €95 billion to the European Union’s GDP and that it can provide significant growth opportunities for the European economy. Users are allowed to run, copy, distribute, study, change and improve software and data, including models by way of free and open-source licences. To foster the development and deployment of AI, especially by SMEs, start-ups, academic research but also by individuals, this Regulation should not apply to such free and open-source AI components except to the extent that they are placed on the market or put into service by a provider as part of a high-risk AI system or of an AI system that falls under Title II or IV of this Regulation.
(12b) Neither the collaborative development of free and open-source AI components nor making them available on open repositories should constitute a placing on the market or putting into service. A commercial activity, within the understanding of making available on the market, might however be characterised by charging a price, with the exception of transactions between micro enterprises, for a free and open-source AI component but also by charging a price for technical support services, by providing a software platform through which the provider monetises other services, or by the use of personal data for reasons other than exclusively for improving the security, compatibility or interoperability of the software.
(12c) The developers of free and open-source AI components should not be mandated under this Regulation to comply with requirements targeting the AI value chain and, in particular, not towards the provider that has used that free and open-source AI component. Developers of free and open-source AI components should however be encouraged to implement widely adopted documentation practices, such as model and data cards, as a way to accelerate information sharing along the AI value chain, allowing the promotion of trustworthy AI systems in the EU.
However, as noted in “Undermining the Foundation of Open Source AI?” there are concerns about the limited scope of the exemption including exclusion of open source foundation models. In addition to exemptions it would be useful to consider and make explicit the way open can be used to fulfill AI Act requirements.
While the EU Act is currently the most advanced in terms of documented regulation, albeit still draft, there are other countries engaged in a similar consideration of AI regulations. The US Senate hearings on AI oversight considered a variety of possibilities including:
The creation of an AI Constitution that establishes values ethics and responsible AI
The need to define ethics, values and responsible AI
Whether a regulating agency (think something similar to Food and Drug Administration) needs to be established
Need for an International Governing Body with authority to regulate in a way that is fair for all entities
Whether AI should be a “licensed” industry? Should government “license” AI much like other industry sectors and professions are licensed? Or should there just be controls on the AI platform and users?
To what extent AI should be a tested and audited industry
The use of something akin to“nutritional labels” as a means of identifying what is in AI systems and models along with additional documentation on their capabilities and areas of inaccuracy
Liability associated with AI
Competitive national interests
AI research
Regulating AI not based on the EU risk categories but rather on being above a certain level of computing or with certain capabilities
How to ensure a thriving AI ecosystem
and many more ideas
Open Across the AI Ecosystem
Open is already a significant driving force across all layers of the AI technology stack. But there is not yet any overarching effort to fully acknowledge its role across the broader AI ecosystem along with proactive suggestions for how to sustain, strengthen and expand on it. In an effort to fill that gap I offer the following Open Across the AI Ecosystem diagram and recommendations.
I’ve placed the AI Tech Stack Layers on the centre of the diagram. From the left AI Research and Development feeds in to all the AI Tech Stack Layers. From the right AI Ethics, Values and Legal including Open and Responsible Licenses, Regulation (national and global), and Community Self Governance feed in. On the far right I’ve added in all important AI Human factors such as Open Networks and Communities, End Users and Public Good.
Open Recommendations Across the AI Ecosystem
I’m keen to see the open community take a more proactive stance around influencing how AI is playing out. Toward that end I offer the following open recommendations across the AI ecosystem. Recommendations are grouped specific to each element of the Ecosystem diagram. I expect there are many more recommendations that could/should be added.
AI Research & Development
Already existing open practices including Open Access, Open Data, and Open Science should be default norms and practices for AI research and development.
Publicly funded AI research and development should include requirements for open
AI Tech Stack Layers
Compute Hardware & Cloud Platform
It is worth considering whether governments should invest in AI Compute Hardware and offer an AI Cloud Platform as open infrastructure to ensure public utility, support of research, and small to medium enterprise innovation. Being dependent on a few large tech providers seems ill-advised and risky. Such a move aligns well with recent statements on Democratic Digital Infrastructure and Invest in Open efforts to get open infrastructure funded as a public utility.
Article 53, Measures in Support of Innovation, of the EU AI Act talks about the creation of AI Regulatory Sandboxes that provide a controlled environment facilitating the development, testing and validation of innovative AI systems for a limited time before their placement on the market or putting into service pursuant to a specific plan. This seems like a tentative step toward open infrastructure. The open digital public infrastructure intent ought to be strengthened and emphasized.
Source Data & Enhanced Data
Existing court cases will clarify whether source data scraped from the web can be used legally based on fair use.
AI relies on the commons. More commons building is needed. AI needs to not just exploit existing commons but contribute to building more.
Creators want to know when their content is being used to train AI. AI developers have a responsibility to inform creators. Allowing creators to opt out is being trialed by AI developers. A more responsible approach is for creators to opt in.
Creator credit may be explicitly required.
Creator compensation may need to be negotiated. See “Comment Submission Pursuant to Request for Comments on Intellectual Property Protection for Artificial Intelligence Innovation” for an example. Owners of structured data sets may charge for AI ingestion.
Consider a social contract requiring any commercial deployment of generative AI systems trained on large amounts of publicly available content to pay a levy. As noted in AI, The Commons, And The Limits Of Copyright “The proceeds of such a levy system should then support the digital commons or contribute to other efforts that benefit humanity, for example, by paying into a global climate adaptation fund. Such a system would ensure that commercial actors who benefit disproportionately from access to the “sum of human knowledge in digital, scrapable form” can only do so under the condition that they also contribute back to the commons.”
It seems crucial from an ethical, responsible and public confidence perspective to require open publishing of what source data went into a model. The nutrition label concept seems self-evident and ought to be simple enough to comply with but specificity of detail and legality issues make this a hot topic requiring attention.
When openly licensed source data such as Wikipedia is cleaned, validated and transformed it ought to be shared back under the same CC BY-SA license.
Models
Responsible open licenses be the preferred means for licensing models
FAIR standards should be used for managing artificial intelligence models. See: “Argonne scientists promote FAIR standards for managing artificial intelligence models”
Each model should have accompanying documentation describing source data, its size, how it was trained, how it was tested, how it behaves, and what its capabilities and limitations are. These requirements ought to be more formally spelled out along with the requirement for this documentation to be openly licensed.
Foundation models should be open source
Application Programming Interfaces
Enhancing models using API data is by default prohibited.
Apps and Applications
The benefits of open such as transparency, fostering innovation and economic activity, and democratizing access address AI ethical and value issues. Open source apps and applications ought to be encouraged and incentivized.
End User Interactions
Enhancing models using end user data is by default prohibited.
End users ought to have the option of allowing their data to be used to enhance open foundational models or open digital AI infrastructures rather than corporate proprietary AI
Generative Outputs
Works produced by a machine or mere mechanical process that operates randomly or automatically without any creative input or intervention from a human author are uncopyrightable. Generative AI content by default is in the public domain
Consider ways of identifying generated works so they are labelled to indicate it is AI generated.
AI Ethics, Values, Legal
Open & Responsible Licenses
The proliferation of licenses and the desire to have them address responsible and ethical issues suggests a need for different licensing bodies to dialogue and coordinate definitions and uses of open licenses across all layers of the AI tech stack.
Open licenses need to transition from being based on Intellectual Property and Copyright law to a broader range of legal means (including contract law) that define use and behaviour
Open licensing needs to broaden from a focus on individual ownership to include joint ownership and collective works
Regulation (National & Global)
Ethics, values and norms, including those based on open, need to be built in up front and across the AI ecosystem. Create an AI Constitution that establishes values ethics and responsible AI.
Regulation should include the use of responsible open licenses as a means of ensuring ethics and values
Establish an AI International Governing Body that works toward ensuring national regulations don't conflict and are fair for all entities
Regulations around AI ought to consider differentiation based on a variety of factors including:
risks to public safety
open vs proprietary
compute power
AI capabilities
number of users
offered for commercial use or not
public good
The EU AI Act should support the use of open source and open science. See: Supporting Open Source And Open Science In The EU AI ACT and associated letter.
The widespread practice of using Terms of Use agreements requiring end users to click “I agree” to terms they’ve never read giving permission to platforms to access and use end user data needs to be stopped through regulation.
Community Self Governance
Open players across the AI ecosystem should come together proactively to define, coordinate and enhance the use of open norms and practices across the AI ecosystem
The community should help define acceptable norms inside, who and how they will be protected/enforced, and what are the responsibilities of the companies that profit are
Adopt an approach based on the principles of commons-based governance. See AI Is Already Out There. We Need Commons-Based Governance, Not a Moratorium
Open is an essential skill and practice in the AI ecosystem (and beyond). Continuing, enhancing and building out open skills and practices ought to be a shared goal along with a shared understanding of the values associated with doing so.
AI Human
Open Communities & Networks need to be supported. Community of practice efforts such as that supported by the Digital Public Goods Alliance (DPGA) and UNICEF provide essential advice and recommendations. See “Core Considerations for Exploring AI Systems as Digital Public Goods” I particularly appreciate the way this discussion paper adds a human layer to the AI Software Stack
End Users need to be given the opportunity to not only use AI but contribute to AI as a form of public good
A central objective should be not just safe, transparent, traceable, non-discriminatory and environmentally friendly AI but AI that generates public good. AI not only needs guard rails but it needs incentives to ensure open and public good as an outcome not just corporate profits
Generating this blog post has been a deep dive over an extended period of time. I acknowledge this is an unusually long ambitious blog post but AI is complex, opens role in it evolving, and my interest is in understanding the big picture. I have learned a huge amount in writing this post and I hope that, in reading it, you have too. My biggest hope in presenting AI from an open perspective is that a greater understanding of the importance of open will emerge and galvanize more efforts to enhance and strengthen it.
Discussion related to this post is taking place on Open Education Global’s discussion forum Connect. Welcome your voice there along with feedback and ideas:
Open Educator as Bartender
After several months of transition let me pick up the thread.
It has been good to take a break. Take time to reflect, recharge, and reimagine open and my role in it. One aspect I have found myself thinking about is “remix”. The central idea of remix is to improve upon, change, integrate, or otherwise remix existing works to create something new. Remix has been a common creative practice throughout human history.
Remix came to the forefront of my thinking during my work at Creative Commons. While remix has a long history it is currently legally prevented by the default exclusive copyright regime applied on intellectual property. In his book “Remix: Making Art and Commerce Thrive in the Hybrid Economy” Lawrence Lessig, one of the cofounders of Creative Commons, adapted the remix concept for the digital age, documenting its benefits and explaining how Creative Commons licenses remove the friction proprietary copyright creates and enable the creative practice of remix.
Remix is an essential element of open education. It is specifically called out as one of the 5R’s of Open Educational Resources (OER):
1. Reuse - Content can be reused in its unaltered original format - the right to use the content in a wide range of ways (e.g., in a class, in a study group, on a website, in a video)
2. Retain - Copies of content can be retained for personal archives or reference - the right to make, own, and control copies of the content (e.g., download, duplicate, store, and manage)
3. Revise - Content can be modified or altered to suit specific needs - the right to adapt, adjust, modify, or alter the content itself (e.g., translate the content into another language)
4. Remix - Content can be adapted with other similar content to create something new- the right to combine the original or revised content with other material to create something new (e.g., incorporate the content into a mashup)
5. Redistribute - Content can be shared with anyone else in its original or altered format - the right to share copies of the original content, your revisions, or your remixes with others (e.g., give a copy of the content to a friend)
While remix is an integral element of open education the actual practice of remixing OER is not widespread practice. It’s always been a bit surprising to me that remix is not a pervasive practice in open education.
In the early days of Open Educational Resources my BCcampus colleague Scott Leslie did a presentation on Open Educator as DJ where he showed how the creative process and workflow of being a DJ can be adopted and adapted by educators working with Open Educational Resources. In Scott’s analogy Search, Sample, Sequence, Record, Perform, and Share are equally effective ways for both a DJ and an open educator to perform their craft. Just as a DJ remixes songs into a compilation an educator can remix OER into a learning experience.
One fun activity I wanted to do in my transition was take a course in bartending. It occurred to me that bartending is all about remix -mixing together different ingredients to create something new. I thought it might be playful and fun to take a course on bartending and see whether there were frameworks, ideas, and practices that could transfer to open education remix. Perhaps the long history of bartending could inform the relatively new and nascent history of Open Educational Resources remix. So in the interests of expanding my own creative practice and learning more about remix I signed up in April 2023 to take the Fine Art Bartender certification course in Vancouver.
The eight day course took place in person in an intensive, very hands-on format roughly following this structure:
Day 1: The basics of bar operations including bartending station setup and bartending equipment. An introduction to vodka and practice making vodka based cocktails.
Day 2: Mixes, garnishes and glassware along with liqueurs and making shooters.
Day 3: Responsible service and a focus on gin including the unique practice associated with making martinis.
Day 4: Geographic origins of rum and tequila along with source ingredients, fermentation/distillation processes. The benefits of ageing and blending and knowing what makes the difference between a basic spirit and premium ones. Practice making rum and tequila cocktails.
Day 5: Focus on different types of whiskies and associated cocktails.
Day 6: Wine including types, serving, pairing, and tasting.
Day 7: Focus on Beer including classifications, changing kegs, dispensing and serving.
Day 8: Final exam. Four rounds of timed cocktail preparations plus written test.
Taking the course generated a whole series of questions and ideas in my mind on how the remix practice of bartending might apply to open education. Below I share a few of those, in italics, as a means of stimulating your own thoughts on the parallels between the two practices. I’d love to do a workshop with other open educators where we collectively explore these questions and ideas.
My introduction to bartending began with an orientation to the basic setup of a bartending station including the tools of the bartending trade - scoop, tongs, shaker, strainer, muddler, spoon, etc., and how to use them. I wondered what the equivalent in open education is? What might an open educator remix station look like and what tools of trade does an open educator use in doing remix?
A central focus of bartending is understanding each of the primary types of spirit - vodka, liqueurs, gin, rum, tequila, whisky, wine, and beer. We learned where and how each spirit is made along with what differentiates a basic spirit from a premium one. In bartending spirits are the central building block around which a drink is made. That led me to wonder: What are the equivalent central building blocks in open education? Do we know where and how OER are made? Is there such a thing as basic open education which we differentiate from premium open education?
Making cocktails involves combining spirits with other mix ingredients to create something new. The remix process follows a prescribed sequence involving specific measures, types of mix, mixing methods, glassware, and garnishes. I asked myself: What are the remix ingredients used in open education? What proportions and measures of open education combine in ways that create the equivalent of a memorable, flavourful, cocktail? What are the equivalents to glassware and garnishes in open education?
In bartending there are four primary ways of making a cocktail; 1. Build on ice, 2. Shake and strain, 3. Shake and pour, 4. Stir and pour. What are four main ways of creating open education?
To make cocktails memorable they are given special names - eg. Cosmopolitan, Tequila Sunrise, Old Fashioned, Moscow Mule, etc. To make them replicable each drink has a specific recipe. Classic cocktails often come down to the same basic ratio: 2:1:1. Two parts spirit, one part sweet, and one part sour, commonly known as the golden ratio. How are types of open education named to make them memorable and replicable? Are there recipes and golden ratio’s in open education?
The bartending course involved extensive practice. We literally made hundreds of cocktails. The final exam required us to do four timed rounds of making cocktails. Each round involved making four cocktails, randomly selected from the approximately one hundred cocktails we learned to make, in four minutes. We had to know from memory what was in each drink, combine and mix the ingredients correctly, serve it in the appropriate glassware, and use the right garnish all within the allotted time. Can open educators quickly, and accurately, remix specific types of open education?
In bartending some drinks are intended to accompany a meal either before, during, or after. What constitutes a “meal” in open education and are there open education experiences designed to meet the before, during, and after aspect of a meal.
Bartending remix is an art and each of us were encouraged to develop our own “style” that includes social engagement with customers at the bar. Is the creation and remix of open education a social activity and what constitutes an engaging open educator style?
These are but a sampling of the thoughts and questions I had. I had to study harder for this course than I had in many years, but it was playful, fun and thought provoking. I believe bartending remix has a long tradition from which open education can learn.
As a corollary to Scott Leslie’s Open Educator as DJ here is an Open Educator as Bartender photo of me at the Fine Art Bartending School.

One surprising thing I hadn’t anticipated in the ensuing weeks and months since I completed my bartending course are the many requests I now get to make cocktails. Friends and family all want to sample my homework or have specific requests for drinks they want me to make. I’ve always been primarily someone who only drinks wine and beer but now social occasions often include me making cocktails as part of the overall experience. I find myself perusing the cocktail menu more when dining out and watching the skill and style of the bartenders. Organizers of an upcoming high school reunion I’m attending have asked me to make a commemorative cocktail -the school colours were red and gold and the school sports teams were the Comets, so I’m busily designing a Comet Cocktail (ideas welcome). There is a element of fun and levity to all this that I wish was part of open education. The creative practice is not just the skillful practice associated with making drinks but learning peoples favourites, encouraging them to try something different, inventing something new, and the social delight of enjoying a cocktail and conversation with others.
Next Steps

Paul’s Shoes Getting Ready for Next Steps
As I write this it has been twelve months since I kicked off a leader succession planning process with the Open Education Global Board of Directors. What a journey it has been. Special thanks to the OEGlobal Board and staff for joining me in pursuing an action based agenda instead of going into a holding pattern. I’m super proud of all the things we’ve done this year and over the five year duration of my tenure.
I'm thrilled to welcome Andreia Inamorato dos Santos as the next Executive Director of Open Education Global. Big congratulations from me. I’m pleased to hand off a high performing Open Education Global and its amazing team of people to her and vow to help her be successful in every way I can.
I have been getting questions about what I’m up to next so I thought I’d share a few of the things I’ve been thinking about.
Andreia starts part time in mid November, transitioning to full time at the start of December. I continue my current role as Executive Director of Open Education Global through to the end of Dec-2022. I like the overlap period between Andreia's start and my departure as it gives us time for onboarding, smooth hand-off, and support. A gradual transition rather than an abrupt one. Through to the end of December I'll be focused on that.
Starting Jan-2023 I transition to being an independent consultant here at paulstacey.global. The .global domain is an upfront expression of my continued interest in working globally.
I started paulstacey.global as a place where I could iterate a calling card, represent my work, and think out loud about what I'll do next. My thoughts are still evolving but here is where I’m at right now.
I intend to continue working in open education. In particular I’d like to work with senior executives who are planning and implementing open education initiatives. Open education has largely been a grassroots movement so far. Now that open education has proven its value and benefits I’m looking to help policy makers and senior leaders add their support through policy, strategy, partnerships and sustainable funding. The open education ecosystem will thrive when top down support meets bottom up adoption.
Much of open education to date has been done as projects. I'd like to work on large scale open efforts. Efforts that position open at the centre of an endeavour not on the periphery. Efforts that seek to transform education.
I'd like to work on initiatives that weave together different forms of open into an overarching strategy. Open Educational Resources, Open Pedagogy, Open Access, Open Data, Open Science, Open GLAM, and Open Infrastructure all share a similar set of underlying principles. I believe there is value in strategically combining them and think their sum as a whole is greater than that of the parts.
Open education is multi-faceted involving things like open licenses, enabling technologies, and special practices. I’d like to continue to work on all of those including emerging work around Artificial Intelligence, micro-credentials, repositories, open pedagogies and other innovations. But I especially want to work on the people side of open education. I want to ensure the motivations, recognition and rewards of being open are fully recognized and enabled. I want to work on helping make collaborations, partnerships and knowledge exchange really happen. I want to continue to build open communities and global networks that connect people together. I want to work on making open education inclusive, accessible, and adaptable in ways that empower teachers and learners.
While my focus will continue to be around open education a lot of my recent thoughts include doing work outside of education.
I like the growing awareness of the benefits of digital public goods. Open education is a form of digital public good. But there are lots of other things that could be open digital public goods too. I’d like to work on initiatives that are intentionally aiming to generate open digital public goods that not only have local and regional value but global value too.
I'd like to work on defining and communicating the economic and social benefits of open. Some years ago I co-wrote a book called “Made With Creative Commons” exploring the many ways organizations across multiple sectors successfully go open while sustaining and growing their enterprise. I’d like to build off and extend that work with the aim of showing value co-creation as a primary means open generates value, not just financial value but value for humanity.
I have lots of ideas about what I want to do next. I look forward to next steps on my journey with Open Education Global and with all of you who seek my help. Feel free to reach out to me by email paul@paulstacey.global or via Contact.
The Elastic Triangle
My views on quality in education are shaped by hearing Sir John Daniel’s speak in Vancouver back in 2009-20210 timeframe on the Iron Triangle (Daniel, Kanwar, & Uvalic-Trumbic, 2009)
THE IRON TRIANGLE MODEL

The origin of this model is that ministers of education seek to provide wide access to high-quality education at a low cost. A goal I think we all share.
The Iron Triangle Model diagram shows current state of provision, with Quality, Access and Cost the three key elements existing in relationship to each other as sides of a triangle.
Strategically there are two characteristics to the Iron Triangle:
1. The triangle is modifiable. You can lengthen or shorten sides of the triangle and see how doing so affects the other sides.
2. The triangle has a fixed-length perimeter. You cannot increase Quality without affecting Access and / or Cost. Changing the length of any one side involves trade-offs with the other sides.
For example, attempts to increase Access may increase Cost and / or reduce Quality.
Or attempts to increase Quality may reduce Access and increase Cost.

The fixed length characteristic of the Iron Triangle suggests there is a zero-sum relationship between Quality, Access, and Cost, hence the term “iron.”
The Iron Triangle was first conceived as a way of modeling traditional classroom based education. Back in 2009-2010, at the time when I first heard Sir John speak about the Iron Triangle, online learning was burgeoning. Daniels, and others (see sample of references at end of this post), did a good job of exploring how online learning could affect the Iron Triangle noting the use of technology allows for improvements in accessibility and quality, as well as economies of scale that classroom education simply cannot attain.
THE ELASTIC TRIANGLE MODEL
In the ensuing years it has become clear that online learning, done well, can render the iron triangle flexible. But while online learning gives the triangle some flexibility it is not until you add in the concept of open education that the triangle becomes truly elastic.
Here’s how.
The central challenge of the iron triangle is to simultaneously widen education access, make quality higher, and lower cost. This desired state looks like this:

One of the most fascinating aspects of the Iron Triangle Model is how Access, Cost, and Quality are defined. Access and Cost are defined quantitatively.
Access = number of students
Cost = per capita costs of education
But what about quality? Quality is more amorphous than access and cost, harder to define in a quantifiable way. A large part of the presentation and description of the Iron Triangle model explores what is meant by “Quality”.
Historically a characteristic of education has been that it is difficult to get into. Here quality is defined as exclusivity. Only those with high marks or other predetermined desirable characteristics (including ability to pay for tuition) are accepted.
Another dimension of quality associated with the place-based classroom lecture model of education is expenditure per student. Here the assumption is that the higher the expenditure on facilities and teachers the better the quality.
A belief that these constitute quality leads to a perception that an institution with tough admission requirements and high fees is a good institution, regardless of what happens within its walls.
Class size, ratio of number of teachers to number of students, and associated extent of teacher student interaction is also used as a proxy for quality with the argument being more students means less teacher student interaction and therefore lower quality unless the cost is increased by hiring more teachers.
More recently the emphasis has shifted to outcomes and examinations of student achievement as measured by standardized tests. Here quality is defined as student success in achieving learning outcomes.
But success in achieving learning outcomes is still predicated on support of some kind. As we move away from place-based learning into online learning three interactions and supports are seen as crucial to student success – student interactions with content; student interactions with other students; and student interactions with teacher.
While some studies show student-content interaction has the greatest effect, studies also show that self-paced independent study without student to student and / or student to teacher interaction leads to higher dropout and incompletion rates. Clearly each type of interaction is important and contributes to student performance. In the online learning context quality entails student interactions with high quality content, high quality student to student interactions, and high quality student to teacher interactions.
Breaking Higher Education's Iron Triangle: Access, Cost, and Quality concludes:
“The aims of wide access, high quality, and low cost are not achievable, even in principle, with traditional models of higher education based on classroom teaching in campus communities. A perception of quality based on exclusivity of access and high expenditure per student is the precise opposite of what is required. One based instead on student achievement enables developing countries to scale up their higher education age participation rates without breaking the bank or fatally compromising quality.”
While online learning makes the Iron Triangle somewhat more flexible I assert that only open education converts the Iron Triangle into an Elastic Triangle.
Let’s start with Cost. The Iron Triangle quantifies Cost as cost of education per capita. This presumes the costs of education are self-contained within a nation, state or region. An essential aspect of open education is the open licensing of teaching and learning resources to be shared with others. This sharing is not constrained by the boundaries of a country but rather is openly shared with everyone around the world. This global sharing converts Cost from a country per capita basis to a global per capita basis. This is a huge change as it means all countries, including developing countries, have access to a large and ever-growing pool of educational resources at no cost. Costs each country has traditionally borne on its own for creating education are now shared and readily available existing materials reduces the current wide scale practice of redundant and repeated development of courses over and over again.
The digital nature of most open educational resources also helps transform the Cost vector from iron to elastic. The costs associated with copying, distributing, and storing digital education resources are close to zero. However, only the unique licenses of open education give everyone the right to freely copy, distribute, retain and modify digital resources. Open education frees education from being fettered and proprietary.
The cost vector can be chunked into costs associated with student interactions with content; student interactions with other students; and student interactions with teacher. In this context it’s important to note that open education is not just about openly sharing resources it also entails open pedagogies which engage students in co-creating content and in doing assignments that contribute to solving global social issues such as the Sustainable Development Goals or contributing to digital public goods such as Wikipedia. Open pedagogies not only make the cost of education elastic but contribute to reducing costs associated with global well-being.
Let’s turn now to Access. The Iron Triangle defines Access as number of students. In the traditional model this is largely defined as enrolments in place-based schools and institutions of higher education. Online learning made the Access vector somewhat more elastic by showing number of students need not be tied to a particular place or facility. Open education is increasing that elasticity even more. Open educational resources are openly shared with everyone. Their use is not constrained to formal academic settings. Open education resources are public goods accessible and available to everyone, even those not formally enrolled as “students”.
In addition to being freely shared open educational resources can be revised and remixed. They can be translated, modified, customized, and adapted to local contexts and needs. This ability to modify and adapt open educational resources ensures they are even more accessible by empowering customization of education to maximize relevance and inclusion. Open education increases access by more accurately ensuring education represents location, culture and identity.
Finally lets turn to Quality. In open education, quality is made more elastic by making it a community driven process. Rather than relying on the subject matter expertise of a single author, open educational resources are typically authored in collaborative teams drawing on a broader cross section of expertise.
The open sharing of open education content, practices and pedagogies ensures they are in essence peer and community reviewed. In open source software development there is a similar practice. Linus's law is the assertion that "given enough eyeballs, all bugs are shallow". The law equally applies to open education. Open education quality is derived by making education transparently visible to all in such a way that others have the agency to use them and errors and improvements can be identified and made by all.
Once education is made “open” the very practice of education can qualitatively improve. The emergence of open education practices and pedagogies particularly around engaging students as active co-creators of knowledge is a unique attribute of open education. Having learners engage in assignments that address real needs of society through the development and sharing of digital public goods dramatically increases student engagement and motivation. It is worth asking whether student contributions to fulfilling social needs and making the world a better place are higher quality evidence of achievement of learning outcomes than those typically assessed in exams and tests. Open education uniquely converts the education process from that of being a passive recipient of education as a service to one in which you are an active participant creating and sharing knowledge in ways beneficial to all.
Stretching Your Thinking
I hope this post has stretched your thinking. I think the Iron Triangle provides an interesting interactive mental model for envisioning different ways we can provide wide access to high-quality education at a low cost.
Thanks for joining me on this thought experiment and hearing me out on my assertion that open education uniquely transforms the Iron Triangle into an Elastic Triangle.
I hope you will join me in discussing this. Questions, ideas, thoughts and suggestions are welcome. Simply click Reply to this post.
****
References
Daniel, J., “Education across space and time”,(2013)
Daniel, J. “Making Sense of Flexibility as A Defining Element of Online Learning”, (2016)
Daniel, S. J., Kanwar, A., & Uvalic-Trumbic, S. (2009). Breaking higher education's iron triangle: Access, Cost, and Quality. Change, March-April Power, M. & Gould-Morven, A., (2011).
Head of Gold, Feet of Clay: The Online Learning Paradox. International Review of Research in Open and Distributed Learning, 12(2), 19–39.
Raymond, E. S., The Cathedral and the Bazaar, (1999)
****
Creator thanks for images used on this page are given on the Attributions page.
“Individual OEGlobal Membership For Life” and Sustaining an Ongoing Relationship
At the May-2022 Open Education Global (OEGlobal) 2022 conference in Nantes, France the OEGlobal Board of Directors gave a public presentation celebrating my five years as Executive Director at OEGlobal. It is moving to hear others list my accomplishments and say I lead with heart, compassion, enthusiasm and a deep dedication to the growth and expansion of open education worldwide. I confess to a certain awkwardness and not knowing how to respond to such thanks except with thanks of my own. I know full well the work I have done is a team effort and am more comfortable with the collective effort being acknowledged than my own individual one, but still, it is wonderful to be acknowledged and thanked.

Paul listening to Martin Dougiamas on behalf of the OEGlobal Board of Directors, give a public presentation celebrating my five years as Executive Director.
As part of that ceremony I was given an honourary “Individual OEGlobal Membership For Life”. What a gift! Although I am stepping down from the OEGlobal Executive Director role at the end of 2022 I intend to continue to be involved in the global open education effort as a consultant at paulstacey.global. Over the years OEGlobal staff and the global open education community have come to feel like “family” to me and as such I’m keen to sustain an ongoing relationship. I see the Individual OEGlobal Membership For Life as an invitation to do just that.
In fact sustaining an ongoing relationship is an integral part of the Leader Succession Plan I developed at the end of 2021. That plan lists the following guiding principles / goals:
Do transition in a way that enhances the caring culture of OEGlobal.
Proactively define a process that has care as a goal.
Own the narrative. Define the timing and process. Control leaks and speculation.
Anticipate and manage emotion and anxiety.
Provide opportunities for expression of appreciation and care.
Create a timeline and phased approach that is good for organization, Board, staff, outgoing Executive Director incoming Executive Director, members, etc.. A kind of win, win, win all around.
Include culture of care approach in announcement and invite Board, staff, and community to come up with additional ways to integrate a culture of care into the process.
Ensure all Board and staff are involved and have a say.
Sustain high performance and continuation of OEGlobal existing plans and initiatives.
Ensure there is an overlap with outgoing and incoming ED for handoff and knowledge transfer.
Sustain an ongoing relationship

Paul expressing thanks for his Individual OEGlobal Membership for Life!
I am very grateful.
Another opportunity to sustain an ongoing relationship emerged not long after, through the wonderful work of my colleague Alan Levine, OEGlobals Director of Strategy and Engagement. Alan has been encouraging all of us to create a voice and presence in OEG Connect - a community space for open educators around the world. He asked us to pick a topic and lead global discussion around it. Alan took the step of creating an OEG Connect Idea Corner, a place for starting a new topic around a specific open education issue or interest area, that can be used as a blogging and discussion platform. I like the way the Idea Corner is inspired by the well known Speakers Corner at Hyde Park in London, UK.
I’ve been thinking a lot about Alan’s call to action. As I transition to an opening education consultant role, I intend to write and blog more, something I did for eight years (2010 to 2018) at https://edtechfrontier.com/. I really like the way blogging lets me share my own analysis of the field and do thought experiments. While I intend to post blogs here at paulstacey.global I want to also be an active voice out on the open web in other open education communities and spaces. It occurred to me that hosting an ongoing discussion with the global open education community around a topic on OEGlobal’s OEG Connect space provides a means for reinvigorating my blogging and sustaining an ongoing relationship with OEGlobal and its community.
There are lots of topics I’d like to explore and dialogue with others about. I decided to start with the topic “Quality Open Education”. Here is an introductory post I wrote in OEG Connect describing my interest in Quality Open Education. To kickoff discussion I wrote a more extensive post I’ve called “The Elastic Triangle”. I’m going to also post The Elastic Triangle here as part of the paulstacey.global blog but if you’d like to engage in discussion around this topic please post a reply in OEG Connect. Your comments, questions and observations are welcome.
Credit for images used on this page are given on the Creator Thanks & Attributions page.
An Open Leadership Transition With Care
A mix of pride, thankfulness, sorrow, and hope tinge this announcement of my decision to transition from Executive Director of Open Education Global, to a new role as an independent open education consultant at paulstacey.global. There are many factors that led to this decision. In the fall of 2021 I travelled from Vancouver Canada where I live back to Ontario, Canada the province where I was born. While there I visited family and high school friends. I was struck by how they had aged and how physical well-being was deteriorating. This forced me to look in my own mirror, reflect on my age (I’ll be 67 in 2022), and take stock of my longevity. I am still healthy, vibrant and alive and have a deep passion for open education. But I came to realize if I want to sustain my efforts I need to have a better work / life balance. I need to make adjustments that nurture my aliveness and passion for open. I need to take care of myself.
A mix of pride, thankfulness, sadness, and hope tinge this announcement of my decision to transition from Executive Director of Open Education Global, to a new role as an independent open education consultant.

“Into the Wide Open” Pacific Northwest kayaking painting by Paul Stacey.
There are many factors that led to this decision.
Open education is growing around the world. With that growth there is a lot of up and coming, emerging talent. I want to make way for, and work with, this new talent. I want to combine my experience with their new ideas and drive to take open education even farther.
Open Education Global has embraced diversity, equity and inclusion as essential elements of open education, including our own organizational culture. As an older, white male, from the global north I see the need for more diverse voices in leadership positions. I want to open opportunities and work with these new diverse leaders.
In the fall of 2021 I travelled from Vancouver Canada where I live back to Ontario, Canada the province where I was born. While there I visited family and high school friends. I was struck by how they had aged and how physical well-being was deteriorating. This forced me to look in my own mirror, reflect on my age (I’ll be 67 in 2022), and take stock of my longevity. I am still healthy, vibrant and alive and have a deep passion for open education. But I need to make adjustments to sustain and nurture my aliveness and passion for open. I need to take care of myself.
The growth of open education has created a need for experienced leaders who can step in and help others with strategic and implementation advice. There are very few global open education consultants in the field and there is a need and growing demand for that kind of help. I look forward to the opportunity to apply my years of leadership and experience to the field of open education in a new capacity.
I want to help governments, institutions, organizations and practitioners with their planning and implementation of open education. I want to help with practical matters and innovation. Over the course of my career I’ve been considered a thought leader. I want to spend more time in that capacity analyzing, writing, and speaking about open, what it means, how it is done, the culture of open, and the process of opening education.
I’m looking to do work helping people weave together the many forms of open, including Open Educational Resources, Open Access, Open Science, Open Data, and Open Source Software into an overarching strategy. If you are imagining an entirely new way of doing education based on education technology, online learning and open education, I can help. If you are seeking to understand the value open education creates including the financial, operational, and cost/benefit aspects, I can help. If you are a cultural or social enterprise looking to integrate open into your work, I can help. I have a special interest in global initiatives and aim to give focused attention and support to a select few clients.
2022 marks my twentieth year leading open education and my fifth year as Executive Director of OEGlobal. What a journey it has been. I am especially thankful to BCcampus, Creative Commons, and Open Education Global for the open work they are doing, for being my places of work over these twenty years, and for the opportunity to be part of them, helping and leading in so many different ways.
My latest work as Executive Director of Open Education Global has been especially meaningful. I am really proud of leading Open Education Global through a period of growth, maturation, and global community building, especially during a pandemic. Five years of creating and hosting global open education conferences, education weeks, open education awards for excellence, global leadership summits, communities and networks is a dream job. Thank you to all those who I have worked beside in these efforts.
I am so pleased with the way Open Education Global focuses on the human dimension of open education with particular attention to collaboration and fostering a culture of sharing. I like the way it operates as a steward connecting the global open education community together for knowledge exchange and value co-creation. I like the way it embodies open in its people, practices, and caring culture.
Amazingly Open Education Global achieves what it does with a small core team of ten people. I am so proud of them. Open Education Global staff are world class talent who understand how to lead open education globally with warmth, encouragement, and welcome. The high performance of Open Education Global is really a testament to them.
Our work together has been a highlight of my life. I care deeply for this team. As I began to think of my own transition I realized I wanted to ensure the Open Education Global team are taken care of and have the opportunity to continue their work and professional growth under a new leader. For that to happen I came to see I must take ownership of my own transition. Being a leader means planning my own leadership transition.
Much work has been done behind the scenes in advance of this announcement, to ensure this transition goes smoothly for all involved. It is February 2022 and the timeline has me transitioning in December 2022. I plan to remain fully engaged as Executive Director of Open Education Global for that entire time. Please join me in this work.
This is a transition, not a retirement. I plan to actively continue my leadership role in open education - just in a different way. Unlike many transitions of this type where the departing leader moves on to something completely different I want to sustain my connection and involvement with the open education field and with Open Education Global. I welcome an ongoing working relationship with the next Open Education Global Executive Director and with all of you, my friends and colleagues in the global open education community.
I look forward to where this journey goes next, over the next ten months in my capacity as Executive Director of Open Education Global, and then as paulstacey.global.
Credit for images used on this page are given on the Creator Thanks & Attributions page.